
Hinweis:
Dieser Blogartikel ist älter als 5 Jahre – die genannten Inhalte sind eventuell überholt.
Visuelle Regressionstests (Visual-Regression-Testing, VRT) sollen es dem/der Software-Entwickler:in erleichtern, im Web-Frontend-Bereich sichere Aussagen zur Qualität der entwickelten Anwendungen zu geben. Dabei werden Screenshots von Benutzeroberflächen gemacht und diese mit einem vorhandenen Referenzsatz verglichen. Auf diese Weise können CSS- und Template-Regressionen erkannt werden, die mit DOM-basierten E2E-Tests nicht zu erkennen sind. Dazu zählen beispielsweise ungewollte Überschreibungen von CSS-Klassen oder Grafiken, die versehentlich nicht mehr sichtbar sind. Damit schließt dieses Testverfahren eine Lücke in der Reihe automatisierter Software-Tests. Mühselige manuelle Testaufwände werden so reduziert und Probleme DOM-basierter E2E-Tests überwunden. Was visuelle Regressionstests in der Praxis leisten können und ob diese tatsächlich DOM-basierte E2E-Tests ersetzen können, versuche ich in diesem Beitrag zu klären.
Im Rahmen meiner Bachelor-Thesis „Visuelle Regressionstests für Web-Frontends“ wurde die Tauglichkeit dieser Testform untersucht. Dazu habe ich vorhandene Tools evaluiert und die vielversprechendsten Lösungen miteinander verglichen. Doe Arbeit bildet die Grundlage für diesen Artikel.
Visuelle Regressionstests
Wie eingangs bereits beschrieben, geht es bei den visuellen Regressionstests (VRT) um die Erkennung von CSS- und Template-Regressionen. Durch automatisierte Pixel-für-Pixel-Vergleiche soll Frontend-Entwickler:innen ermöglicht werden, Änderungen im Layout einer Web-Applikation visuell nachzuvollziehen und ungewollte Änderungen besser erkennen zu können.
Neben den üblichen Teststrategien wie Unit-, Integration- und End-to-End-Testing werden Web-Anwendungen meist manuell getestet. D.h., Entwickler:innen oder Tester:innen klicken eine Anwendung händisch durch und simulieren damit Use-Cases der Endanwendung. Diese Methode ist zeitintensiv und nur schwer skalierbar. Je größer die Anwendung, desto mehr Zeit und damit Geld muss in das manuelle Testen investiert werden. Dies ist fehleranfällig und wenig effizient. Menschen können marginale Veränderungen einfach übersehen, was einer Maschine nicht passieren kann. Dieses Phänomen nennt sich Change-Blindness. In der folgenden Abbildung unserer zu testenden Anwendung (dabei wird auf die TodoMVC-App zurückgegriffen) fehlt im neu aufgenommenen Screenshot (Mitte) beispielsweise das Input-Element zum Abhaken des To-Do-Eintrags. Diese marginalen Veränderungen sind vom menschlichen Auge nur schwer zu erfassen.

Für das VRT muss es möglich sein, Screenshots einer Web-Anwendung automatisiert zu erstellen und diese dann mit einem Referenzsatz vorhandener Screenshots zu vergleichen, um Regressionen zu detektieren.
Workflow
Der Ablauf oder Workflow von visuellen Regressionstests ist unterteilt in vier Stufen, wobei die Stufen drei und vier optional und davon abhängig sind, ob es Unterschiede in den Screenshots gibt. Die zu testende Anwendung wird hier als „AUT“ (Application-Under-Test) bezeichnet:
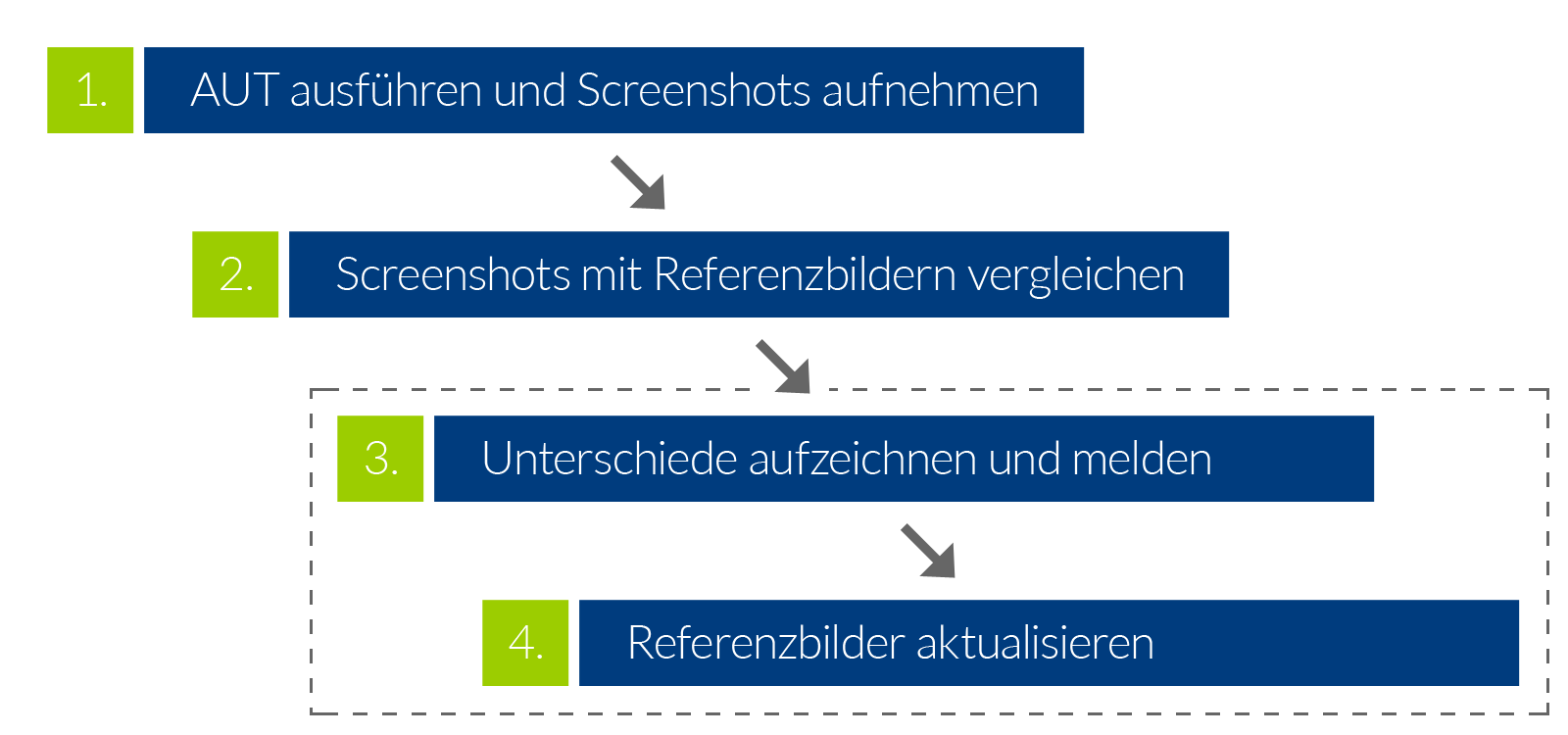
- Im ersten Schritt wird die AUT in einer kontrollierten Teststellung ausgeführt. Dazu werden entweder reale Daten benutzt oder es wird auf Testdaten zurückgegriffen. Dann werden die in den Tests beschriebenen Teile der Anwendung aufgenommen und gespeichert. Das bedeutet, es werden verschiedene Status von verschiedenen Seiten der AUT in Form von Screenshots festgehalten.
- Anschließend werden im Schritt zwei die aufgenommenen Screenshots mit einem bereits existierenden Satz an Referenz-Screenshots verglichen. Diese Referenz-Screenshots werden als Baseline bezeichnet. Sie werden vor dem ersten Test aufgenommen und manuell auf ihre Korrektheit überprüft. Nach dieser initialen Prüfung ist ein automatisierter, maschineller Abgleich der im Test aufgenommenen Bilder mit der Baseline möglich.Die Prüfung der Screenshots geschieht in den meisten Fällen ohne weitere Logik – Pixel für Pixel. Das bedeutet, es werden die zueinandergehörigen Bilddaten übereinander gelegt und dann Reihe für Reihe, Pixel für Pixel die RGB-Farbdaten miteinander verglichen.
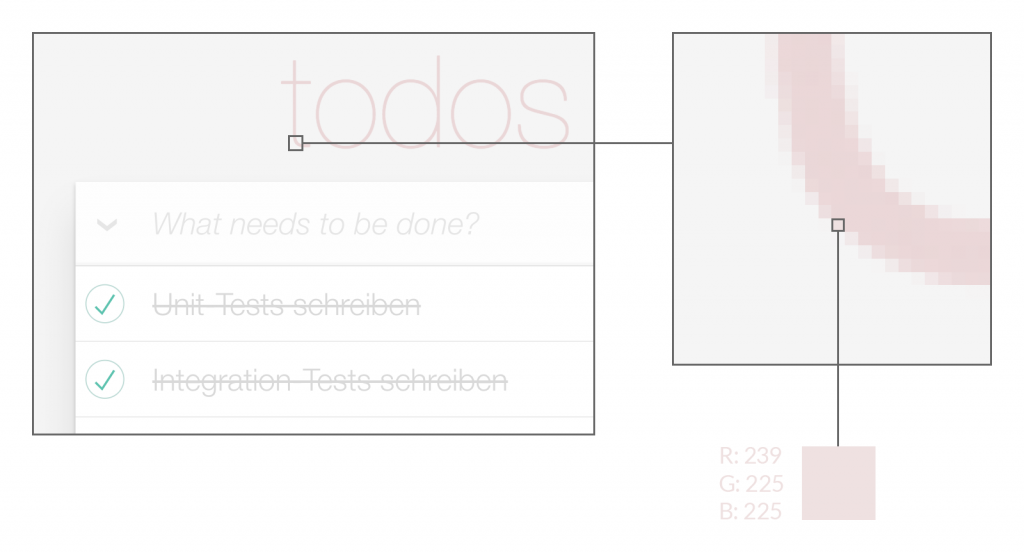
Abbildung: Pixel-Zusammensetzung eines RGB-Bildes - Der dritte Schritt beinhaltet das Aufzeichnen und Melden von gefundenen Unterschieden in den verglichenen Screenshots. Dabei wird eine Kopie der jeweiligen Baseline gemacht und die sich unterscheidenden Pixel Rot (oder in einer anderen auffälligen Farbe) in dem neu erzeugten Bild markiert. Zusätzlich zu dem neu angelegten Differenzbild können auch Metadaten wie beispielsweise die Anzahl der unterschiedlichen Pixel für eine weitere Nutzung gespeichert werden.
- Im letzten Schritt geht es darum, die im Vergleich als „fehlgeschlagen“ markierten Screenshots manuell zu prüfen. An dieser Stelle kann festgestellt werden, ob die Veränderungen in der AUT beabsichtigt waren oder nicht. Waren die Änderungen gewollt, zum Beispiel weil ein neues Feature implementiert wurde, wird der neu aufgenommene Screenshot als neue Baseline übernommen. Die Baseline lässt sich dabei bequem per Git versionieren. Waren die Änderungen nicht gewollt, konnte der Test erfolgreich einen Fehler erkennen und dieser kann nun behoben werden.
Einordnung und Kritik
Visuelle Regressionstests gehören zu den E2E-Tests. Da wir uns hier lediglich auf die Verwendung im Web-Frontend-Bereich beschränken, werden UI-Tests in diesem Artikel synonym mit E2E-Tests verstanden. UI-Tests zählen in der Qualitätssicherung zu den Black-Box-Ansätzen. Black-Box-Testtechniken nehmen das zu testende System als Ganzes wahr. Sie haben keinerlei Kenntnis über Details des zugrundeliegenden Quellcodes. Die einzigen beiden Faktoren, die hierbei beeinflusst bzw. abgeglichen werden können, sind Ein- und Ausgabewerte der Software. Black-Box-Tests entsprechen damit weitestgehend der Sicht, die der Endnutzer auf das Software-Produkt hat. Damit eignen sich besonders User-Stories zur Identifizierung geeigneter Testszenarien.
Anders als bei den Unit- und Integrations-Tests werden bei den UI-Tests durch den Black-Box-Ansatz jedoch einige Probleme offenkundig. Dazu ist es sinnvoll, sich die Test-Automation-Pyramide nach Mike Cohn genauer anzuschauen.

Mike Cohn beschrieb 2010 in seinem Buch „Succeeding with Agile“ eine dreistufige Pyramide für eine effektive und effiziente Automation von Software-Tests. Die unterste Stufe, und damit die Basis der Pyramide, bilden die Unit-Tests. Sie repräsentieren den größten Anteil an Tests, der nach Cohn auch der komfortabelste ist. Sie haben extrem kurze Laufzeiten und liefern äußerst granulare Fehlermeldungen zum Ursprung des Problems. Die mittlere Stufe repräsentiert die Service- oder Integration-Tests, also jene Testfälle, die mehrere Module „unterhalb“ des User-Interfaces integriert testen. Die oberste, dritte Stufe der Pyramide bilden die UI-Tests, von denen, nach Cohn, so viele wie nötig und dabei so wenig wie möglich geschrieben werden sollten. Dabei bemängelt er, dass diese instabil, teuer und zeitaufwändig seien. Zudem entstünden dadurch Redundanzen. Da für UI-Tests immer die vollständige Code-Basis aufgerufen wird, werden auch immer Funktionalitäten getestet, die durch Tests der darunterliegenden Stufen einfacher und schneller zu testen sind.
Die von Cohn erwähnte Instabilität der UI-Tests gründet auf dem Problem, den Status der AUT zu kontrollieren. Wurde zur Zeit der Testausführung beispielsweise das CSS, Bilder oder DOM-Elemente noch nicht vollständig geladen, schlagen die Tests fehl, obwohl die Anwendung korrekt funktioniert. Diese und ähnliche Fehler werden False-Negatives genannt. In der Praxis wird jedoch deutlich häufiger der Begriff „False-Positives“ synonym dafür verwendet. Je nach Interpretation, ist beides korrekt. In diesem Artikel wird dazu False-Positives gesagt. Bei „klassischen“ oder auch „DOM-basierten“ E2E-Tests werden False-Positives meist durch fehlende DOM-Elemente verursacht. Im Prinzip unterscheiden sich diese Tests in der Ausführung nicht von visuellen Regressionstests. Für diese wird ebenfalls die komplette Anwendung für ihre Ausführung geladen. Daraufhin wird dann auf die Existenz bzw. die Abwesenheit von DOM-Elementen bzw. auf deren Inhalt im Browser getestet. False-Positives beim VRT werden zusätzlich durch Unterschiede im Rendering der Inhalte im Browser induziert. Weiter unten wird darauf noch einmal detaillierter eingegangen.
Der höhere Zeitaufwand bei UI-Tests ist nicht nur durch eine längere Ausführungsdauer bedingt, sondern auch durch weniger nachvollziehbare Fehlerquellen. Im Gegensatz zu Unit-Tests können UI-Tests meist nicht auf eine bestimmte Stelle im Code verweisen, um deren Ursache zu beheben. Durch den Black-Box-Ansatz wird lediglich das finale Ergebnis im Browser betrachtet. Dieses wiederum ist jedoch meist Ergebnis eines Zusammenspiels von Templates, Controllern und Services.
Je länger die Ausführung der Tests dauert, je schwerer diese zu warten sind und je instabiler sie laufen, desto geringer ist die Wahrscheinlichkeit, dass Entwickler UI-Tests wiederholt ausführen. Dies wiederum führt tendenziell zu einer höheren Fehlerrate in der Entwicklung und damit zu einer längeren Entwicklungszeit.
Aus den aufgeführten Gründen ist der produktive Einsatzzweck von visuellen Regressionstests etwas umstritten. Es gibt einige Vertreter der Meinung (z. B. Pete Hunt, Autor des VRT-Tools Huxley für die Instagram-Web-Anwendung; die Weiterentwicklung des Werkzeugs wurde mittlerweile eingestellt), dass mit den vorhandenen Lösungen Tests dieser Art lediglich als Code Review Tool taugen, nicht aber als vollwertiges Testwerkzeug. D.h., sie sehen deren Einsatz nicht integriert in eine automatisierte Teststellung, sondern eher als lokales Werkzeug zum visuellen Abgleich der vorgenommenen Änderungen.
Um visuelle Regressionstests als ernstzunehmende Testmethode etablieren zu können, muss es folglich das Ziel sein herauszufinden, welche Szenarien sinnvollerweise zu prüfen sind, gleichzeitig die Stabilität der Tests zu gewährleisten und deren False-Positive-Rate möglichst gering zu halten.
Evaluation vorhandener VRT-Tools
Insgesamt wurden im Rahmen meiner Thesis etwas mehr als 30 Testing-Tools untersucht. Dabei wurden sowohl Open-Source- als auch kommerzielle Lösungen betrachtet. Über mehrere Filterstufen hinweg wurden Tools aussortiert, die entweder nicht mehr aktiv gepflegt werden oder nicht den Anforderungen (siehe nächster Abschnitt) entsprechen. Am Ende sollten dann drei VRT-Tools übrig bleiben, welche im Rahmen eines Implementierungsteils benutzt wurden, um Tests für eine reale AngularJS-Anwendung zu schreiben. In diesem Blog-Artikel werden die Tests anhand der oben gezeigten TodoMVC-App implementiert.
Anforderungen
Die folgenden Anforderungen an die Testing-Tools wurden im Rahmen der Abschlussarbeit erarbeitet:
| Funktionale Anforderungen | Nicht-funktionale Anforderungen |
|---|---|
|
|
Unter den Basisfunktionen bei den funktionalen Anforderungen sind dabei die vier Schritte des zuvor beschriebenen Workflows zu verstehen. Viele Tools decken dabei nur einen Teil dieser Basisfunktionen ab. Spectre ist beispielsweise lediglich eine Web-Anwendung für den Bildvergleich. Das bedeutet, es gibt eine Schnittstelle, über welche Bilddaten an die Anwendung gereicht werden können, die dort miteinander verglichen und dann ausgewertet werden. Deshalb ist es hier sinnvoll die Stärken der einzelnen Werkzeuge zu verknüpfen.
Die erweiterten Funktionen zielen auf einen sinnvollen produktiven Einsatz ab. Dazu sollte mit der Anwendung interagiert werden können, um diese in den gewünschten, zu testenden Status zu versetzen (z. B. korrekt ausgefülltes Formular in einem Bestellprozess). Weiter soll es möglich sein, beispielsweise per CSS-Selektor, gezielt nur Teile der Anwendung als Screenshot zu speichern. Der ansonsten gängige Ansatz ist es, die vollständige Seite, entweder nur den im Browserfenster sichtbaren Bereich oder die komplette scrollbare Höhe, aufzunehmen. Die wichtigsten Punkte bei den erweiterten funktionalen Anforderungen sind die letzten beiden. Die Erkennung von False-Positives soll die Stabilität der Tests gewährleisten und die Automatisierung die Integration in eine bereits vorhandene Teststellung.
Bei den nicht-funktionalen Anforderungen ist ein besonderer Fokus auf die Robustheit zu legen. Dieser ist eng verknüpft mit der Erkennung von False-Positives und soll die Akzeptanz bei Entwickler:innen verbessern.
False-Positives
False-Positive-Ergebnisse, oder kurz False-Positives, können viele Ursachen haben. Neben gewollten Änderungen (Features), die zu erwartenden Fehlern im Vergleich der Screenshots führen, gibt es Fehlerursachen, welche ungewollt, für das menschliche Auge nicht oder nur kaum zu erkennen und technischer Natur sind. Dazu zählen beispielsweise Anti-Aliasing und Image-Scaling. Des weiteren führen dynamische Inhalte, Verschiebungen von Inhalten und Verzögerungen beim Laden einzelner Komponenten der AUT zu fehlerhaften Testergebnissen. Diese False-Positives gilt es zu erkennen und zu vermeiden.
Es gibt unterschiedliche Ansätze False-Positives zu verhindern. Wie das Tool LooksSame von Yandex orientieren sich viele an der menschlichen Wahrnehmung der Inhalte. Das bedeutet, Farbabweichungen, die für einen Menschen kaum sichtbar sind, werden nach dem Modell CIE-DE2000 herausgerechnet. Auch die Unterschiede in den Pixel-Rasterungen von Kanten (Anti-Aliasing) wird von den meisten Tools gut erkannt und verursacht somit keine False-Positives. Problematisch wird es allerdings, wenn sich beispielsweise der Inhalt um nur einen Pixel nach unten verschiebt. Damit wird, obwohl sich inhaltlich nichts verändert hat und diese Verschiebung durch das menschliche Auge nicht wahrnehmbar ist, die gesamten verschobenen Pixel als „Fehler-Pixel“ markiert. Um diese Art der False-Positives in den Griff zu bekommen, bieten einige Testing-Tools die Möglichkeit, eine Mismatch-Toleranz anzugeben. Diese Mismatch-Toleranz misst den Prozentsatz an Pixel, der sich unterscheiden darf, bevor der neu aufgenommene Screenshot als „unterschiedlich“ zur Baseline markiert wird. Dies birgt jedoch ein Problem: Je höher natürlich die Auflösung des Screenshots, desto mehr Pixel dürfen sich unterscheiden, ohne dass „Alarm“ geschlagen wird. Damit ist die Mismatch-Toleranz mit Vorsicht zu genießen. Ein intelligenterer Ansatz wäre es, Inhalte zu detektieren (z. B. via OCR oder Layout-Elemente als Objekte klassifizieren) und dann festzustellen, ob sich inhaltlich oder strukturell was am Status der AUT verändert hat. Dies erfordert einen deutlich höheren Aufwand in der Bildverarbeitung und wird aktuell nur von dem kommerziellen Dienst Applitools Eyes angewendet.
Tool-Auswahl
Für die Auswahl der richtigen Testwerkzeuge wurde, neben den oben aufgeführten Anforderungen, speziell auf zwei Faktoren viel Wert gelegt. Zum einen sollte der Technologie-Stack für Frontend-Entwickler:innen nicht unnötig erweitert werden und zum anderen sollten die Tests in realen Browsern (nicht nur in Headless-Browsern wie beispielsweise PhantomJS) ausführbar sein. Ersteres bevorzugt eine JavaScript API und letzteres eine Selenium-Basis der Werkzeuge. Die Selenium-Basis ermöglicht das Testen der Eigenheiten der einzelnen Browser. Sofern man keine eigene Infrastruktur mit Test-Geräten hat, kann hier auf Dienste wie BrowserStack oder Sauce Labs zurückgegriffen werden.
Das Team von Yandex hat mit seinem Tool Gemini eine solide Lösung für das Problem der visuellen Regressionen entwickelt. Mit einer guten Community und Performance war dieses ein Teil der Auswahl im Rahmen der Thesis. In der originalen Auswahl war auch das Tool WebdriverCSS im Zusammenspiel mit WebdriverIO für die Browser-Automatisierung und Applitools Eyes für den Bildvergleich. WebdriverCSS wird jedoch nicht mehr aktiv weiterentwickelt. Stattdessen wird das von Applitools entwickelte SDK eyes.webdriverio.javascript für WebdriverIO verwendet. Applitools Eyes ist das einzige kommerzielle Tool in der Auswahl und bietet über seine Web-Anwendung die Möglichkeit, die Ergebnisse der Bildvergleiche zu inspizieren. Mit Applitools Eyes soll vor allem gezeigt werden, wo die Vorteile einer intelligenten Bildverarbeitung im Bildvergleich liegt.

Implementierung der Tests
An dieser Stelle sollen besonders zwei Dinge gezeigt werden:
- Unterschied von DOM-basierten zu visuellen Regressionstests
- Problematik der False-Positives bei visuellen Regressionstests
Als Testszenario wird dafür jeweils die „Abhaken“-Funktion der To-Do-Liste unser Test-App verwendet. In der folgenden Abbildung ist das Szenario abgebildet. Links ist der initiale Status der AUT zu sehen und rechts der Zielzustand, der getestet werden soll.
![Abbildung: Testszenario für die "Abhaken"-Funktion; [1] initialer Zustand der AUT, [2] zu testender Status der AUT](https://www.inovex.de/wp-content/uploads/2018/03/testszenario.png)
DOM-basierte vs. visuelle Regressionstests
Für den ersten Teil der Implementierung soll zu dem Testszenario der dazugehörige DOM-basierte Test mit Protractor und der visuelle Test mit Gemini implementiert werden.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
describe('todo-check', () => { beforeEach(() => { browser.get('http://localhost:8080/examples/angular2/'); }); it('should mark "UI-Tests schreiben" as done and update UI accordingly', () => { let todoCount = element(by.css('todo-app .todoapp .footer span.todo-count strong')); let todoEntry = element(by.css('ul.todo-list li:last-child')); let todoEntryCheckbox = todoEntry(by.css('input')); todoEntryCheckbox.click() .then(() => { expect(todoCount.getText()).toBe('0'); expect(todoEntryCheckbox.isSelected()).toBe(true); expect(todoEntry.getAttribute('class')).toMatch('completed'); }); }); }); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
gemini.suite('todo-check', (suite) => { suite.setUrl('http://localhost:8080/examples/angular2/') .setCaptureElements('html') .before((actions, find) => { this.todoEntryCheckbox = find('ul.todo-list li:last-child input'); this.todoEntryLabel = find('ul.todo-list li:last-child label'); }) .capture('todo-ui_tests-done', (actions, find) => { actions.click(this.todoEntryCheckbox); }); }); |
Nachdem für diesen Test die Baseline erstellt wurde, wird eine Änderung im CSS vorgenommen, welche „ungewollte“ Auswirkungen auf die Darstellung hat. Dazu wurde das padding für alle input Elemente mit 50px überschrieben (vgl. nachfolgende Abbildung des Ergebnisses des visuellen Regressionstests). Da es sich hier um eine reine Änderung am CSS handelt, bekommt der DOM-basierte Test davon nichts mit und läuft weiterhin ohne Fehler durch. Da nach dieser Änderung jedoch die input Elemente in andere klickbare Bereiche hineinragen, ist das UI für eine:n Endnutzer:in nicht mehr ohne weiteres zu bedienen und damit die Funktionalität eingeschränkt.

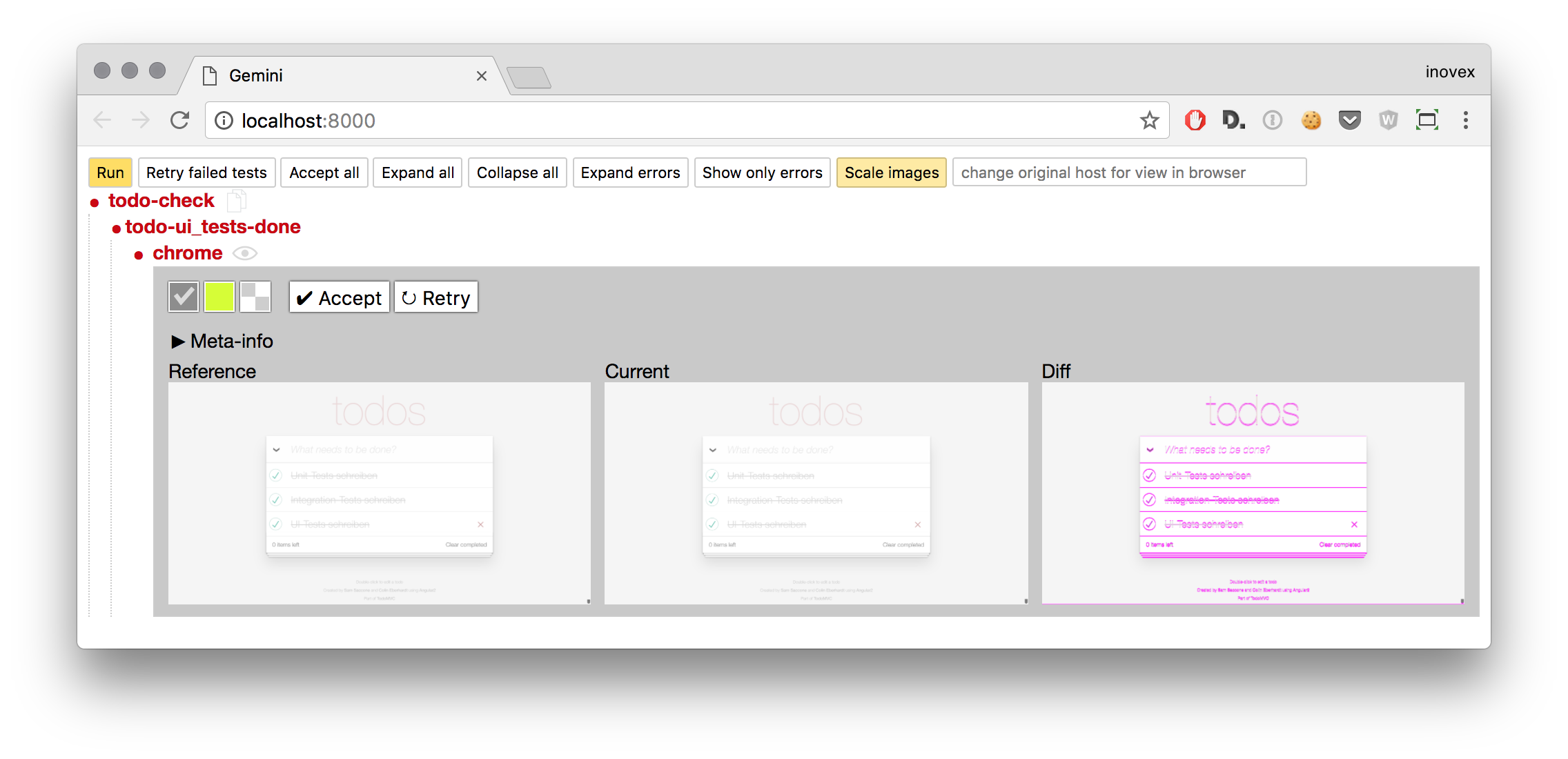
Das Ergebnis eines erneuten Testdurchlaufs mit Gemini zeigt, dass das Tool die Regression erkennt und der Test fehlschlägt. An dieser Stelle hat der/die Entwickler:in dann die Möglichkeit, die Fehler zu beheben oder gewollte Änderungen über den „Accept“-Button in die neue Baseline zu übernehmen.
In der Code-Länge unterscheiden sich die beiden Implementierung zuerst nur minimal. Möchte man allerdings bei den DOM-basierten Tests auch prüfen, ob die anderen To-Dos nach dem Durchlauf des Tests den korrekten Zustand haben und nicht beeinflusst wurden, kommt für jedes Element mehr Code hinzu. Bei den visuellen Tests bekommt man diese zusätzliche Abdeckung aller sichtbaren UI-Elemente kostenlos dazu (vgl. nachfolgende Abbildung).
![Abbildung: Testabdeckungen: [1] DOM-basierte UI-Test, [2] visueller Regressionstest](https://www.inovex.de/wp-content/uploads/2018/03/dom-vs-vrt-testabdeckung.png)
Problematik der False-Positives
Im zweiten Teil der Implementierung soll zusätzlich zum Gemini-Test ein weiterer visueller Test mithilfe von WebdriverIO und Applitools Eyes erstellt werden. WebdriverIO ist eine auf Node.js basierende Implementierung des W3C-WebDriver-Protokolls und soll dabei unterstützen, die AUT in den zu testenden Zustand zu bringen. Dieser Zustand wird dann in Form eines Screenshots festgehalten und per HTTP-Request an Applitools Eyes gesendet, wo der Bildvergleich stattfindet. Die Baseline wird wieder im Voraus aufgenommen und automatisch bei Applitools Eyes gespeichert. An dieser Stelle sollen die beiden Tool-Setups (Gemini vs. WebdriverIO + Applitools Eyes) verglichen werden.
Am Gemini-Test hat sich nichts verändert. Der einzige Unterschied ist die eingebaute Änderung in der To-Do-App, die im zweiten Durchlauf erkannt werden soll. Auch hierbei handelt es wieder um eine reine CSS-Änderung. Dafür wird der margin-top der section.todoapp (entspricht der To-Dos-Liste; Titel ist auch abhängig von dessen Position) um ein Pixel vergrößert. D. h. der komplette Inhalt rutscht einen Pixel weiter nach unten.
Das Ergebnis des Gemini-Tests ist in der nachfolgenden Abbildung zu sehen. Der Test schlägt fehl und markiert alle nicht-weißen Pixel als Fehler-Pixel, obwohl der Unterschied zwischen der Baseline (bei Gemini „Reference“ genannt) und der aktuellen Aufnahme für den Menschen nicht sichtbar ist. Eine weitere Schwierigkeit dieser Art der False-Positives ist, dass die Fehlerquelle nicht direkt ersichtlich ist. Wäre der Hintergrund der To-Do-Liste nicht weiß, sondern hätte beispielsweise eine Struktur (mit einer Höhe > 1 Pixel), wäre nicht nur der Inhalt im Differenzbild hervorgehoben, sondern die komplette Fläche ab der Höhe des verschobenen Pixels.
Die Implementierung des Tests mit WebdriverIO im Zusammenspiel mit Applitools Eyes sieht dabei wie folgt aus:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
async function main() { const wdio = require('webdriverio'); const browserOptions = { remoteHost: 'http://localhost:4444', desiredCapabilities: { browserName: 'chrome', chromeOptions: { args: [ 'disable-infobars' ] } } }; const driver = wdio.remote(browserOptions); let browser = driver.init(); const { Eyes, Target } = require('@applitools/eyes.webdriverio'); let eyes = new Eyes(); eyes.setApiKey('APPLITOOLS_API_KEY'); try { await eyes.open(browser, 'todo-mvc', 'todo-check', { width: 1024, height: 680 }); await browser.url('http://localhost:8080/examples/angular2/'); await browser.click('ul.todo-list li:nth-child(3) input'); await eyes.check('Main page', Target.window()); await eyes.close(); } finally { await browser.end(); await eyes.abortIfNotClosed(); } } main(); |
Das Ergebnis des Bildvergleichs mit Applitools Eyes ist hier abgebildet:
![Abbildung: Ergebnis des Tests mit WebdriverIO und Applitools Eyes: [1] Match-Level: Exact, [2] Match-Level: Strict](https://www.inovex.de/wp-content/uploads/2018/03/fp-applitools_eyes.png)
- Strict (default): Imitiert die Wahrnehmung des menschlichen Auges (siehe z. B. CIE-DE2000)
- Exact: Pixel-für-Pixel-Verlgeich
- Content: Ignoriert Styling und Pixel-Unterschiede durch Anti-Aliasing
- Layout: Ignoriert inhaltliche Änderungen (z. B. bei dynamischem Inhalt)
Die wohl am häufigsten benutzten Level sind „Strict“ und „Layout“. In unserem Beispiel reicht das Standard-Level „Strict“, um den durch die Pixelverschiebung provozierten False-Positive zu verhindern. Möchte man jedoch dynamische Inhalte bzw. lediglich strukturelle Aspekte einer AUT testen, eignet sich das Level „Layout“ für den Bildvergleich. Dabei wird die Struktur des Layouts mithilfe ausgefeilter Algorithmen in der Bildverarbeitung erkannt und auf Regressionen geprüft. Dafür liegt der Fokus im Bildvergleich auf neuen, fehlenden oder fehlplatzierten Objekten in der Layout-Struktur. Nachfolgend wird dazu ein kurzes Beispielszenario dargestellt. Dabei hat sich zum einen die Länge eines der To-Dos geändert und zum anderen die Platzierung der Überschrift.
![Abbildung: Ergebnis des Tests mit WebdriverIO und Applitools Eyes: [1] Match-Level: Exact, [2] Match-Level: Layout](https://www.inovex.de/wp-content/uploads/2018/03/fp-applitools_eyes-2.png)
Lessons learned
Was soll getestet werden?
Wichtig an dieser Stelle ist das Identifizieren sogenannter Validation-Points. Damit sind die Status gemeint, die eine hohe Priorität für die Endnutzer:innen haben oder zu einem kritischen Workflow wie beispielsweise dem Check-out-Prozess gehören. Erstere können zum Beispiel anhand von Nutzungsstatistiken erkannt werden.
Ein weiteres Kriterium für einen Validation-Point ist, wie viele interaktive UI-Elemente die Benutzeroberfläche hat. Je mehr Interaktionsmöglichkeit das UI bietet, desto anfälliger ist dieses für Fehler und dafür diese beim manuellen Testen zu übersehen.
Web-Anwendungen, die wenig verschiedene UIs und kaum interaktive Elemente besitzen, taugen selbstverständlich weniger dazu, den zusätzlichen Aufwand für die Tests zu investieren.
Ein weiterer Use-Case, bei dem es sich lohnt, visuelle Regressionstests für eine bestehende Anwendung zu schreiben, ist der einer CSS-Refaktorisierung. Mit VRT kann das UI vor dem Umbau in einer Baseline „eingefroren“ und dann das CSS überarbeitet werden.
Gemäß der Testing-Pyramide von Mike Cohn sollte VRT als reines CSS- bzw. GUI-Testing-Werkzeug gesehen werden. VRT ist keine sinnvolle Methode, um Business-Logik zu validieren.
Wie soll getestet werden?
Um immer mit aktuellen Browser-Versionen und den unterschiedlichen Browser-Typen testen zu können, sind auf Selenium basierende Tools zu bevorzugen.
Die besten Erfahrungen wurden mit WebdriverIO in Kombination mit Applitools Eyes für den Bildvergleich gemacht. WebdriverIO bietet eine schnelle Ausführungsgeschwindigkeit und gleichzeitig eine einfache Integration in JavaScript-basierte Web-Projekte.
Besonders wichtig ist der vorsichtige Umgang mit Mismatch-Toleranzen. Am besten wird darauf vollständig verzichtet.
Wie für DOM-basierte Tests gilt auch bei den visuellen Regressionstests die Kapselung der Tests von der Implementierung. Dies wird durch die Nutzung des Page-Object-Pattern realisiert, welches leider häufig missachtet wird und zu redundanten Pflegeaufwänden der UI-Tests führt.
Ein weiterer wichtiger Punkt sind
wait -Statements in den Tests. Sofern diese sich nicht auf konkrete Elemente im DOM beziehen (z. B. bei Gemini mit
actions.waitForElementToShow(
Wann soll getestet werden?
Der optimale Zeitpunkt zum Testen auf Systemebene ist vor der Integration eines neuen Features in eine bestehende Anwendung. Das bedeutet zum einen, dass VRT kein Ansatz für TDD (Test-Driven-Development) sein sollte, da sich gerade zu Beginn eines Projektes die Baseline regelmäßig stark verändert. Zum anderen ist damit gemeint, dass speziell Pull oder Merge Request von Feature Branches auf beispielsweise den Develop oder Master Branch (vgl. GitFlow) als Zeitpunkt für den visuellen Vergleich mit der Baseline sinnvoll sind. Dazu lassen sich die getesteten Tools problemlos in Build-Umgebungen einbinden und somit automatisieren.
Neben dem Einsatz als eine Art Akzeptanz-Test, bietet sich der visuelle Vergleich auch als Monitoring-Werkzeug an. Dafür werden in regelmäßigen Zeitabständen automatisiert Screenshots einer produktiven Web-Anwendung gemacht und diese auf Regressionen geprüft.
Ausblick
Visuelle Regressionstests haben ihre klaren Schwächen im effektiven Vergleich zweier Screenshots in der Bildverarbeitung. Bis auf Applitools Eyes nutzen alle evaluierten Werkzeuge ausschließlich den Ansatz des direkten Pixel-Vergleichs. Dafür sind bei einigen Tools zusätzlich Algorithmen zur Vernachlässigung von Anti-Aliasing-Effekten bzw. geringen Farbdifferenzen implementiert. Jedoch bietet keine der Open-Source-Lösungen einen Ansatz zur Layout-Validierung.
Zusätzlich wäre es wünschenswert, Änderungen in den Screenshots selektiv in die Baseline übernehmen zu können. Dafür wäre jedoch ebenfalls eine Erweiterung der Bildverarbeitung notwendig, um Pixel-Gruppen zu identifizieren.
VRT in der Mobile-Application-Entwicklung ist zudem ein interessantes Thema. Über Appium (Selenium-Pendant für mobile Endgeräte) lässt sich der gleiche Test-Workflow in der Mobile-Application-Entwicklung umsetzen.
Fazit
Automatisierte Tests, die für die unterschiedlichen Ebenen der Programmstruktur geschrieben werden, sollen helfen, die Software-Qualität zu verbessern. Trotzdem wird es für Software-Entwickler:innen zunehmend schwieriger, Aussagen über die Qualität der von ihnen entwickelten Anwendungen zu treffen. Das Problem dabei sind die zunehmend komplexer werdenden Systeme. Im Fall der Web-Frontend-Entwicklung entspricht dies hochdynamischen grafischen Benutzeroberflächen. Inhalte werden nicht mehr nur statisch angezeigt, sondern in Teilen dynamisch nachgeladen und aktualisiert. Das Internet verbreitet sich dabei als Software-Plattform immer rasanter. Desktop-Anwendungen werden häufiger in Form von Web-Anwendungen neu implementiert und damit steigt auch der Grad der Interaktionsmöglichkeiten, die Web-Frontends bieten müssen. Trotzdem werden gerade diese kaum durch automatisierbare Tests geprüft. Die Kernfragen meiner Abschlussarbeit, auf der dieser Artikel basiert, zielen folglich darauf ab, den Grund hierfür herauszufinden und eine Aussage zu treffen, ob das Gebiet der visuellen Regressionstests Abhilfe schaffen kann.
Die Implementierung und Integration von UI-Tests mit unterschiedlichen Werkzeugen hat gezeigt, dass visuelle Regressionstests einen gangbaren Weg darstellen, Benutzeroberflächen zu validieren. Diese sind nicht nur weniger aufwändig zu entwickeln und zu pflegen als DOM-basierte UI-Tests, sondern bieten zusätzlich eine Erkennung von CSS- und Template-Regressionen.
False-Positives lassen sich mit ausgereiften Algorithmen in der Bildverarbeitung kompensieren und die automatisierte Interaktion mit den unterschiedlichen Web-Browsern ist mittlerweile gut ausgebaut und ausreichend zuverlässig. Wird in den Tests mit der Anwendung interagiert, um in den zu testenden Zustand der AUT zu kommen, wird funktional das gleiche getestet wie bei DOM-basierten Tests. Damit sind visuelle Regressionstests nicht nur eine komplementäre, sondern, aus meiner Sicht, auch ersetzende Lösung für DOM-basierte UI-Tests.


