
Notice:
This post is older than 5 years – the content might be outdated.
At inovex we use Apache Airflow as a scheduling and orchestration tool in a wide range of different applications and use cases. One very common use case is building data pipelines to load data lakes, data platforms or however you want to call it.
When we are working in a public hyperscaler environment (such as AWS) there are many different options process the data itself. We could do the actual work on Airflow itself, Glue, EMR clusters, lambda functions, plain EC2 instances, a Kubernetes (K8s) cluster managed by our operations team, and so on.
In this article I want to show some details of a hybrid approach that we use to load and manage a data lake for one of our personalization projects to handle heterogeneous workloads. It definitely helps if you already have some basic knowledge of Apache Airflow, AWS EMR and Kubernetes.
Our Use-Cases, Architecture and Technologies
The project I’m talking about is all about personalization on an end user-facing application, available for a wide range of different platforms. We use different data sources to calculate different styles of recommendations and characteristics of users which are used to personalize the product. The data sources we consume are mainly tracking data that reveals insights on the customers behaviour on the platform and metadata about the users themselves (subscriptions, cancellations, …) and about the items the users interact with on the platform.
The project was started on AWS with cloud-agnostic, flexibel and future-proof development in mind. These were the reasons we decided to switch from high-level AWS services (like Glue) to lower-level services like EMR more and more over time. To give you a basic idea of what we are doing and how we are doing things, the following picture shows a high-level view of our architecture (at least for the classic data lake or “batch“ part of it, that I’m talking about in this post):

Our data is stored in multiple levels of abstraction in S3. To deliver our data products to the frontends, we use DynamoDB tables (by the way: this is not a good example of being cloud-agnostic). All processes are scheduled and orchestrated by one single Airflow instance per environment (dev, staging, pre-production, production), hosted on a simple EC2 instance.
Before we started to use a more hybrid approach, every job was written as a PySpark job. We decided to schedule one dedicated EMR cluster per job to have flexibility on configuration (for example different hardware configurations, different software versions and independent and isolated environments for every job).
What Does Hybrid Workload Actually Mean?
More and more use cases have popped up that needed the use of libraries/features that aren’t available in Spark or simply don’t need the power of a large distributed computation framework like Spark. One example is scikit-learn which was used by our data scientists to build some of the ML models. Us data engineers faced the challenge that Spark ML doesn’t offer all algorithms/models. Some of the implementations are simply performing really bad in comparison to scikit models or are not flexible enough in terms of configuration. Another use case where Spark seemed to be the wrong tool are pretty small tasks that only process a few megabytes of data.
Some of our jobs still needed to aggregate large amounts of data for pre-processing. One first idea was to keep the heavy lifting (pre-processing) in Spark, transform the Spark dataframes to Pandas and do the actual model training or predictions on the driver node. We experimented with df.toPandas() to handle this. But also in conjunction with Apache Arrow optimizations it led to various memory problems for large workloads (by time of our experiments, the Apache Arrow integration was not well documented and felt still like a kind of beta; by the time of writing this post, it seems to be more stable and we definitely should have a look at it again).
Our Hybrid Pipeline Approach
We then started to build our first hybrid pipeline that makes use of both worlds: Spark for the hard work, and plain python scripts for the scikit parts. The only missing part was a runtime environment for the scikit/python scripts. Using the master node of the EMR cluster felt like a bad idea because we didn’t want to influence all the processes going on the master by a ML model training or prediction job. EC2 seemed to be too low-level since we then would’ve needed to configure and manage a lot of stuff we’re not experts in. So we decided to switch to tiny and lightweight containers scheduled on a self-hosted Kubernetes cluster which is fully managed by a vertical team (of course you can run your containers on any container platform you like). With that approach, all jobs are independent of each other and can have isolated resources. The necessary data exchange between single stages is done with intermediate S3 buckets, as shown in the following illustration:
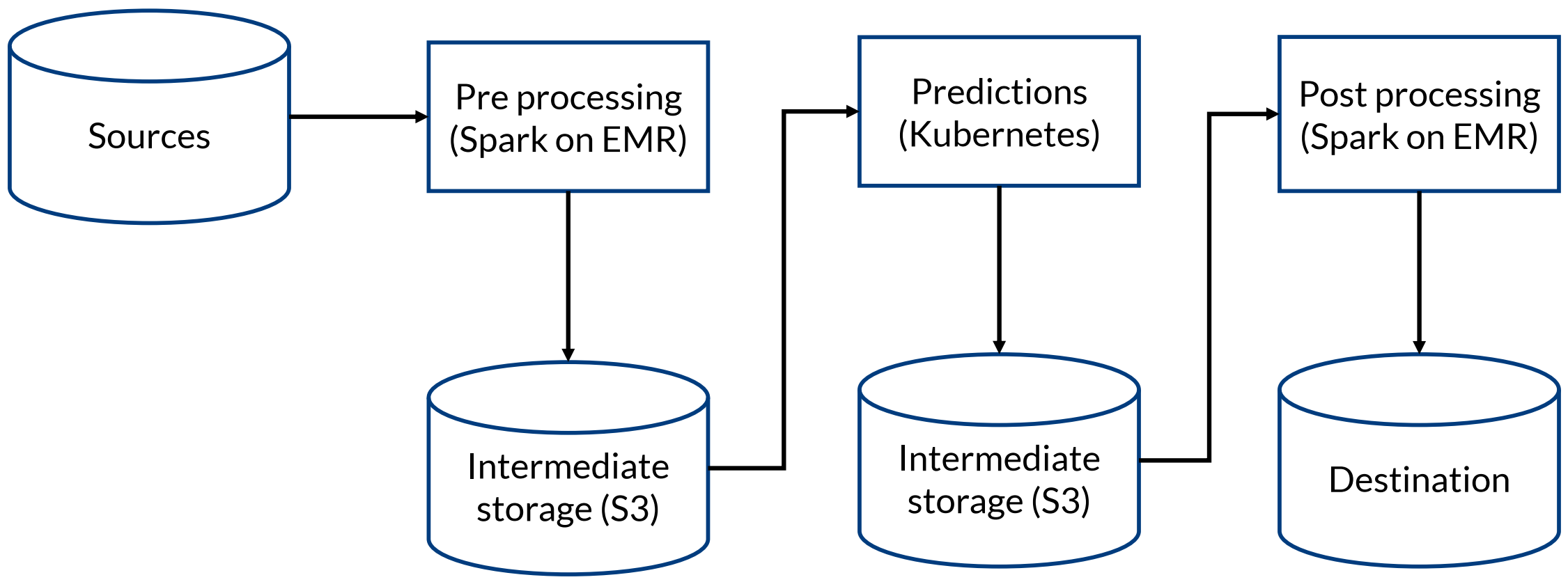
This gives us more overall calculation speed than transforming from Spark to Pandas and vice versa (at least for really large jobs) and has the advantage of high flexibility regarding the used frameworks or libraries for the intermediate pipeline steps.
Implementation Details
Airflow is a very generic technology and thus gives us the flexibility to build and integrate any runtime we want. But we tried to find three basic Airflow DAG-patterns and all of our jobs follow one of them:
- Spark-only processing:Start EMR cluster → schedule Spark job → terminate EMR cluster
- K8s-only processing:Schedule K8s job
- Generic processing:Start EMR cluster → schedule Spark job (pre-processing) → schedule K8s job (ml training/predictions) → schedule Spark or K8s job (post-processing) → terminate EMR cluster
This has the effect that we need to use only a very small number of different Airflow operators that are all more or less easy to use and high-level in the sense of integration into Airflow and the cloud environment. Furthermore, we strictly separate business logic from scheduling code. That way we could easily switch the scheduling tool, runtime environment or cloud provider. For example, if we wanted to switch from AWS to GCP, the only thing we need to do is to switch the EMR operators to—for example—Google Dataproc operators. In addition, it leads to faster development cycles because we implemented all the Airflow pipeline logic into generic libraries that can be re-used over and over again. One more positive aspect of the code separation is that we can deploy Airflow code and the business logic itself separately. This post describes a similar approach of using only a small number of different Airflow operators and shows more aspects in detail.
A Basic Airflow App Folder Template
All files that belong to one specific DAG are collected in one common sub-folder with the following structure:
|
1 2 3 4 5 6 |
my_app job_configs my_job.json cluster_configs my_cluster.json my_app_dag.py |
This keeps all the files in a clear and repeatable structure and helps developers as an initial starting point for their DAGs.
Running an EMR Job
With our own EMR cluster DAG library mentioned in the previous chapter starting an EMR job from Airflow is as simple as:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
app_folder = configuration.conf.get("core", "dags_folder") + "/my_app" job_config_folder = app_folder + "/job_configs" cluster_config_folder = app_folder + "/cluster_configs" dag = DAG( dag_id="my_dag", schedule_interval="0 1 * * *", template_searchpath=cluster_config_folder ) my_cluster = Cluster(dag=dag, cluster_name="my_cluster") my_cluster.add_step(job_config_file=f"{job_config_folder}/my_job.json") my_cluster.build_sequential_flow() |
One DAG built this way is shown in the example below:
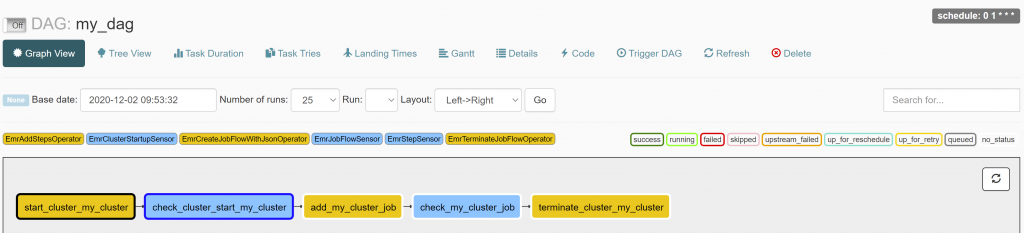
As you can see, there are a few different tasks in between the task itself: We have to actively wait for the cluster to come up before we can add the job, and we have to wait for the job to be finished before terminating the cluster. To ensure that no cluster keeps running and idling a long time without doing work, we add the parameter trigger_rule="all_done" to the cluster termination task. This way, the cluster also terminates after a job has failed.
The cluster config is loaded via Airflow’s template mechanism and is just a JSON file with all the configurations needed for starting the EMR cluster (for example instance types and counts, EMR version, path to bootstrap scripts, …). The job config file is also a simple, templated JSON file which looks similar to this:
|
1 2 3 4 5 6 7 8 9 10 11 |
{ "SparkArgs": { "--deploy-mode": "cluster", "--packages": "mysql:mysql-connector-java:8.0.11" }, "ScriptPath": "{{ config.DEPLOYMENT_BUCKET }}/my_app/my_app.py", "JobParams": { "--stage": "{{ config.ENV }}", "--execution_date": "{{ ds }}" } } |
It’s basically parsed into a spark-submit command which is then executed on the EMR cluster as a step with the generic command-runner. The parsed spark-submit command for the example above would look like this:
|
1 2 3 4 5 6 |
spark-submit \ --deploy-mode cluster \ --packages mysql:mysql-connector-java:8.0.11 \ s3://my-deployment-bucket/my_app/my_app.py \ --stage prod \ --execution_date 2020-12-24 |
We can also plug any arbitrary tasks into the automatically built workflow this way:
|
1 2 3 4 5 6 7 8 9 |
my_cluster = Cluster(dag=dag, cluster_name="my_cluster") add_my_job, check_my_job = my_cluster.add_step(job_config_file=f"{job_config_folder}/my_job.json") my_cluster.build_sequential_flow() some_upstream_task = BashOperator(...) some_downstream_task = BashOperator(...) some_upstream_task >> add_my_job some_downstream_task >> check_my_job |
The resulting DAG looks like this:

Running a K8s Job
As you can see in the previous chapter, there is a lot of boilerplate stuff to do for an EMR workflow and it requires a lot of overhead until the job itself can be started. For jobs that should be scheduled as Kubernetes Pod, we use the KubernetesPodOperator. None of the overhead is needed here. It directly launches Pods, continuously checks their state and gathers logs from the containers.
The following code snippet shows how we start jobs as a Kubernetes Pod from Airflow:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
docker_tag = Variable.get("docker_tag") resources = { "request_memory": "8000Mi", "limit_memory": "8000Mi", } my_k8s_job = KubernetesPodOperator( name="my_k8s_job", task_id="my_k8s_job", dag=dag, image=f" arguments=["--date", "{{ ds }}", "--stage", "{{ config.ENV }}"], namespace=" config_file="/home/ec2-user/.kube/config", get_logs=True, in_cluster=False, do_xcom_push=False, resources=resources, image_pull_secrets=" is_delete_operator_pod=True, ) |
We build pretty lightweight Docker containers per job that simply contain the Python code, needed dependencies, and run it. The latest Docker version tag is injected into Airflow during the deployment process via Airflow variables. Please note: Kubernetes recently set the Docker runtime to deprecated. That doesn’t mean you can’t use Docker containers in Kubernetes or Docker as a development tool. But if you’re interested in other container solutions, you can find a comparison of alternative tools in this article.
One interesting parameter is get_logs=True. With that set, you can see all the logs printed in your container in the Airflow U.
With do_xcom_push=True you can pass results from your container to the downstream tasks via the xcom concept. Please note that this is only suitable for smaller results due to the fact that xcom values are stored in the meta database of your Airflow installation.
One problem we faced with the KubernetesPodOperator is this bug which lets your long-running Pod crash when it doesn’t produce any logs for a while. We can overcome this issue with a background thread periodically writing a dummy alive log to the logs (as suggested in a Jira ticket).
Another recommendation I can give is to set is_delete_operator_pod=True so that the finished Pod gets cleaned afterwards and doesn’t pollute your Kubernetes namespace with terminated Pods. Be careful: You lose all the logs and details of failed Pods. Most of the time, the collected logs in Airflow are detailed enough for debugging. If you want to keep all those details in Kubernetes itself for a while, you can configure Kubernetes garbage collection to do the job automatically.
Please note that Kubernetes has the concept of a Job which fits very naturally to our concept of one-time jobs. It would be a great idea to implement a Pod Operator for Airflow based on the Kubernetes Jobs-API. At time of writing, that’s not available, yet.
Overall Example DAG
The following code snippet shows a complete example of a hybrid workflow orchestrated as Airflow DAG.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
app_folder = ( configuration.conf.get("core", "dags_folder") + "/app_" ) job_config_folder = app_folder + "/job_configs" cluster_config_folder = app_folder + "/cluster_configs" default_args = { "start_date": datetime(2020, 12, 1), } dag = DAG( dag_id="generic_model_pipeline_example", default_args=default_args, schedule_interval="0 1 * * *", template_searchpath=cluster_config_folder, ) # This is the location in S3 which is used for data exchange between the single pipeline steps job_params = { "s3_result_path": "s3://intermediate-results-bucket/recommendation-job/intermediate_results" } example_cluster = Cluster(dag=dag, cluster_name="example_app") add_preprocess_step, check_preprocess_step = example_cluster.add_step( job_name="example_preprocess", job_config_file=f"{job_config_folder}/example_preprocess_job.json", job_params=job_params, ) resources = { "request_memory": "8000Mi", "limit_memory": "8000Mi", } docker_tag = Variable.get("docker_tag") recommend_step = KubernetesPodOperator( name="example_recommendation_task", task_id="example_recommendation_task", dag=dag, image=f"url.to.our.harbor/repo_name/my_recommendation_task:{docker_tag}", arguments=[ "--s3_result_path", job_params["s3_result_path"], "--source_path", add_preprocess_step.task_id, ], namespace="my-k8s-namespace", config_file="/home/ec2-user/.kube/config", get_logs=True, in_cluster=False, do_xcom_push=False, resources=resources, image_pull_secrets="name-of-pull-secret", is_delete_operator_pod=True, ) add_postprocess_step, _ = example_cluster.add_step( job_name="example_postprocess", job_config_file=f"{job_config_folder}/example_postprocess_job.json", job_params={**job_params, **{"source_path": recommend_step.task_id}}, ) example_cluster.build_sequential_flow() check_preprocess_step >> recommend_step >> add_postprocess_step |
As you can see, every task writes its intermediate results to S3 under a key named after its task ID. We feed every task with the task ID of its predecessor, where it can find the data it needs for its job. The rendered DAG looks like this:

Summary
In this article I showed that we face different types of workloads that we want to run in the cloud or on other arbitrary runtimes. I presented one possible concept of orchestrating hybrid workloads with Airflow. There are a lot more options how you can handle heterogeneous jobs, but this way works very well for our project setup, as we initially started with EMR and needed a quick way to integrate other types of jobs into our pipelines without migrating all the existing Spark jobs to a new runtime environment like for example Spark on Kubernetes or similar.


