dmTech Creation of a hybrid BI architecture with Big Data components
Technologies





Customer benefits
- Digitization of retail
- innovative solutions
- Efficient handling
The emphasis is on the development of innovative solutions: for the online shop and customer and employee apps as well as for the IT infrastructure in the dm stores, distribution centres and headquarters. With a number of innovations, a key role is played by the efficient handling and analysis of large amounts of data in order to produce added benefits from the combination of data sources (Big Data).
Against this background, dmTECH is working with inovex on various projects, each of which open up new Big Data possibilities. The aim of the ‘BI Analytics’ project was to enhance the capabilities of an existing Data Warehouse solution with Big Data technologies. Innovative use cases – such as a scalable solution for individual receipt analysis – are set to be used in the new hybrid architecture.
The BI experts at dmTECH have been operating a Data Warehouse infrastructure for a number of years, in which data from various areas of the company are gathered, processed and made available centrally by means of controlled ETL processes. This approach is suitable for structured data that is supplied via standardised ETL development modules for the purposes of harmonised analyses across the company. New analysis-related demands are frequently motivated by two different aims. Firstly, it should be possible to efficiently process larger quantities of potentially less well-structured data or raw data. Secondly, it should be possible to use a streaming approach to supply results virtually in real time. Both aspects can be addressed by Big Data technologies, such as Apache Hadoop, which complement the range of functions of the Data Warehouse solution.
As part of this case study, the individual receipt analysis platform should be presented as a specific project for implementing the hybrid approach.
For regulatory and fiscal reasons, dmTECH must be in a position to present historical receipts for analysis – as part of a tax audit, for example. In this regard, very large quantities of receipts are constantly being produced, which are continually fed into the IT systems as a data stream from every dm store. The aim of the individual receipt analysis is to process the large quantities of data within these data streams in order to permit real-time reporting.
In specific terms, it is of interest to obtain selective insights and information about individual receipts. This may relate to a request for one specific receipt (‘I need the receipt dated 24.12.2018 from store 123 issued at 11.33 a.m. at checkout 2’) or an aggregated view of parts of the data (‘I need the total sales of all receipts from calendar week 13 in 2018 that contain products from merchandise group 12’).
The Apache Hadoop ecosystem features a number of components that meet the requirements very well – particularly the scalable storage and processing of large quantities of data.
One specific tool, for example, is Apache HBase, which enables the scalable storage of (raw) receipts with simultaneous efficient access to individual receipts.
In later stages, the data for bulk processing can be stored in the Hadoop Distributed File System (HDFS) and analysed and processed in a highly performant manner with Apache Spark. Apache Phoenix and Apache Hive are suitable for access via an SQL interface, permitting integration with existing BI front ends and thus interactive reporting.
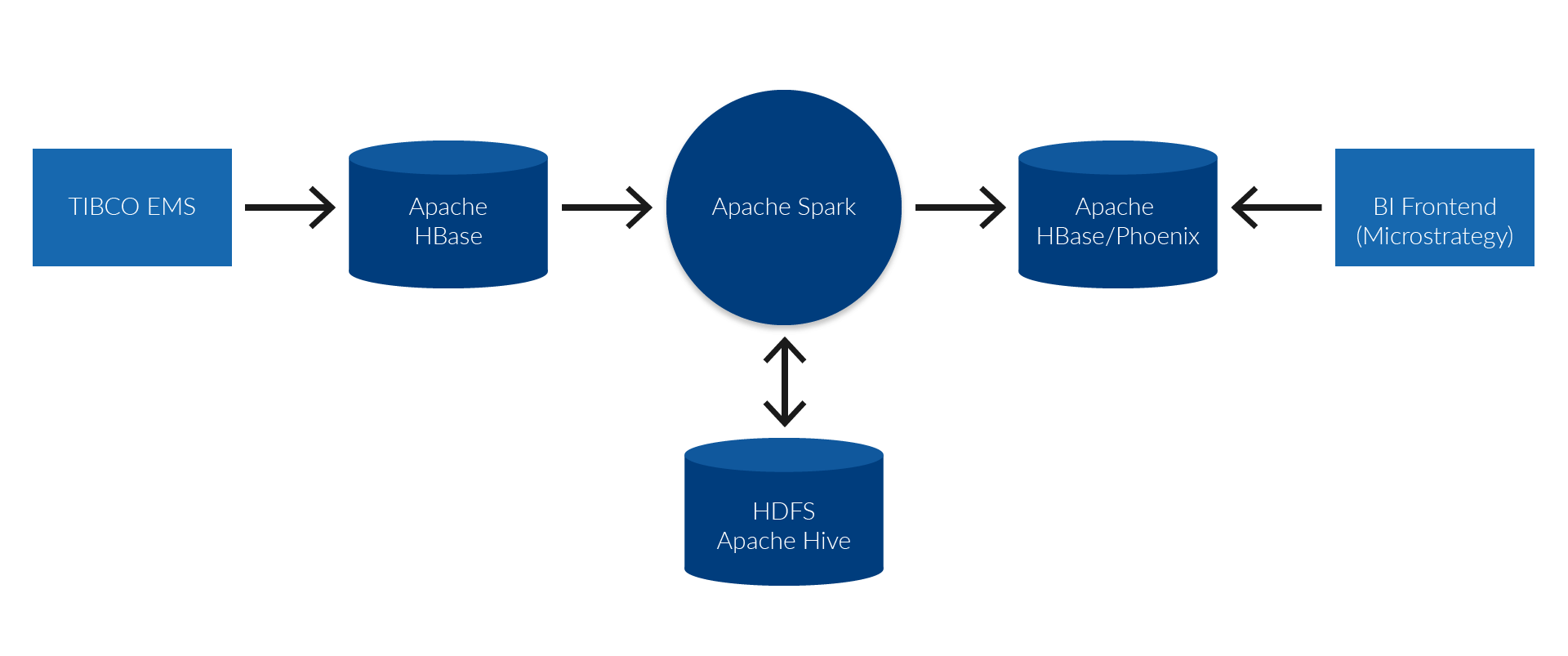
From a technical perspective, the receipts from the tills of every store are sent via a store server to the existing middleware solution (TIBCO EMS) at dmTECH. A connector has been set up in this middleware. This writes every single receipt directly to the NoSQL system Apache HBase, ensuring that every single receipt is available as raw data in the analytics solution shortly after it has been created. The receipts can be identified within HBase by means of a unique key, allowing the direct deduplication of data, for example, in the event of multiple deliveries. However, when the receipts are stored in this raw form, they cannot be analysed in a performant manner along all relevant dimensions.
In order to make this possible, Apache Spark reads the raw data before it is transformed and written to the final analysable table via various intermediate steps.
In turn, this data is stored in HBase and made available via the SQL layer Apache Phoenix. Intermediate results are held in the Hadoop Distributed File System (HDFS) in the form of Hive tables in order to guarantee efficient calculations.
All components along this processing chain are distributed systems that possess good scaling characteristics through parallel processing. As such, if the quantity of data increases, for example, calculation nodes can be added to the Hadoop Cluster in order to be able to continue processing within an acceptable time frame. The following diagram shows the interaction of the system components.
Analysis
Apache Phoenix uses the performant NoSQL database HBase for storage. The analysis layer permits the fast analysis of data and the generation of corresponding key figures. One important aspect of both technologies is the fact that individual tables in HBase/Phoenix can be optimised in advance for certain analysis models, comparable to the creation of indices in relational databases. Future reporting requirements can also be well covered thanks to the performant option of generating new analysis tables in Spark from the raw data or intermediate layers.
The core of the analysis
The existing BI tool Microstrategy is used as an interface for analysing the individual receipts. This is also used in many other use cases at dmTECH and is correspondingly well established. Microstrategy is integrated with the data in the analytics solution via Apache Phoenix. This integration with Hadoop is advantageous, because Phoenix provides an SQL interface that can be accessed via standard JDBC. This includes an abstraction of the underlying HBase database’s complex access mechanisms. As a result of these standards (SQL and JDBC), it is easy for external systems to access Hadoop.
Dieses Projekt war für uns der Türöffner zur Anwendung des Data-Lake-Konzeptes auf Basis der Hadoop Technologien. Der hybride Ansatz ermöglicht uns das effiziente Speichern großer Datenmengen, um diese in Realtime zu analysieren und Einsichten gewinnen zu können. Mit inovex an unserer Seite haben wir erfolgreich die bestehende DWH/BI-Infrastruktur um eine State-of-the-Art Data-Lake-Landschaft erweitert und damit die Basis geschaffen, um anstehende Analytics-Anforderungen umsetzen zu können.
Thomas Herwerth
Produktverantwortlicher DWH/BI, dmTECHSummary and reusability
The outlined enhancement of the existing BI architecture at dmTECH using components from the Hadoop ecosystem permits the performant derivation of key figures from an extremely extensive quantity of data. This approach thus enhances the options of the existing platform. Furthermore, the horizontal scalability means that it can be cost-effectively adapted to growing data quantities and more complex analyses in the future. The new systems are seamlessly integrated into the existing landscape via the SQL and JDBC standard interfaces. For further use cases, this makes it possible to decide on an individual basis which technology best suits the requirements – Hadoop or the existing infrastructure. This hybrid approach can therefore combine the best of both worlds and thus increase the number of overall options.
The focus on Hadoop will also pay off in future projects and further use cases. There is a great deal of interest in the analysis of key figures in real time, for instance. A corresponding real-time dashboard can be created with the aforementioned Hadoop frameworks by adding the Apache Nifi streaming framework, for example, making it possible to analyse sales in near real time using the receipts.