
TL;DR:
This article explores how synthetic data can boost small object detection. Traditional models often struggle because training data usually features large objects. The shown solution involves outpainting with generative AI (like Stable Diffusion) to embed smaller objects into realistically generated backgrounds. Experiments showed a significant performance improvement in detecting tiny objects (e.g., cars in the KITTI dataset). This versatile approach is also applicable in medicine, manufacturing, and retail to make AI systems more robust for real-world conditions.
Object detection is a vital component in a variety of fields, including autonomous driving, surveillance, medical imaging, and robotics. It’s the technology that allows computers to „see“ and interpret the world around them, identifying objects in images and videos with increasing accuracy. But what happens when the objects we need to detect are small or distant? This is where the challenge of small object detection comes into play.
Traditional object detection models often struggle with smaller objects because training datasets typically contain images where objects occupy a large part of the image, making generalization difficult. Think of autonomous vehicles needing to identify tiny pedestrians in the distance, or medical scans searching for minuscule anomalies. Inaccurate detection can lead to critical errors.
My bachelor thesis explores a solution to this problem: using AI and synthetic data generation to enhance object detection models, particularly for small objects. By creating artificial datasets with a focus on smaller object sizes, we can train models to „see“ smaller objects. This blog post will delve into how this technology works and its potential applications in various fields.
Motivation: The challenge of object detection in the real world

This article presents the experiments and results of my bachelor thesis. The thesis was carried out with the support from inovex. It explores a novel idea for improving the performance of object detection models by augmenting the datasets with partly synthetic image data.
Why is computer vision / object detection important?
Computer vision is one of the most transformative fields in modern artificial intelligence, enabling applications ranging from autonomous driving and medical imaging to surveillance and industrial automation. At the core of many of these applications lies object detection—the ability of a machine learning model to locate and identify objects in an image or video. While deep learning models have achieved remarkable accuracy in detecting objects, a persistent challenge remains: the disparity between training data and real-world deployment.
What is the problem?
A crucial aspect of this challenge is the size of objects in images. In many practical applications, objects of interest appear much smaller in real-world scenarios than they do in standard training datasets. Consider the case of traffic monitoring or autonomous driving, where vehicles at a distance appear as small objects in a large scene. Object detectors trained on datasets with predominantly large and well-defined objects struggle to generalize to these smaller instances, leading to suboptimal performance.
Real-world use case: KITTI dataset
KITTI is a very popular dataset for evaluating the performance of object detectors trained for detecting cars. The dataset is made from photos from a car on the streets. One example can be seen below, in which the car drives on a street with parked cars on each side. One crucial objective of an autonomous car in this situation would be to detect the cars with the goal of driving around them. Notably, the relative sizes of the cars range from big, when they are close to the camera, to relatively small when they are further away.

Trainings dataset: Stanford cars
The Stanford Cars dataset is a comprehensive collection of images of cars. It also includes labels, i.e., information about the location of the car in the image. Below are some examples from the dataset with the bounding box label drawn. One can see here that the cars are situated in different environments than as they would be seen in real-world traffic. This also has the effect that the photo is taken from a much closer distance to the car, making it smaller relative to the overall image area.
Difference in size of the car relative to the image
When we look for datasets to use for training an object detector model, we rarely find enough images that represent situations similar to those that are relevant for the use case. The Stanford Dataset is one example that significantly differs from the images found in the real-world dataset KITTI.
Over the last decade, the research field of computer vision has made huge strides in developing more performant model architectures to detect objects. These methods require extensive expertise in deep learning model architecture and considerable computational resources, making them expensive and time-consuming.
A more straightforward and scalable solution lies in dataset augmentation—modifying or expanding the training data to better reflect real-world conditions. If a model struggles to detect small objects because it has never seen them during training, why not provide it with training examples that simulate real-world conditions?
My bachelor’s thesis explored this exact question: Can synthetic data be used to bridge the gap between training datasets and real-world applications? More specifically, can we generate augmented datasets that improve small object detection performance without altering the model itself?
The idea: Synthetic data augmentation with outpainting
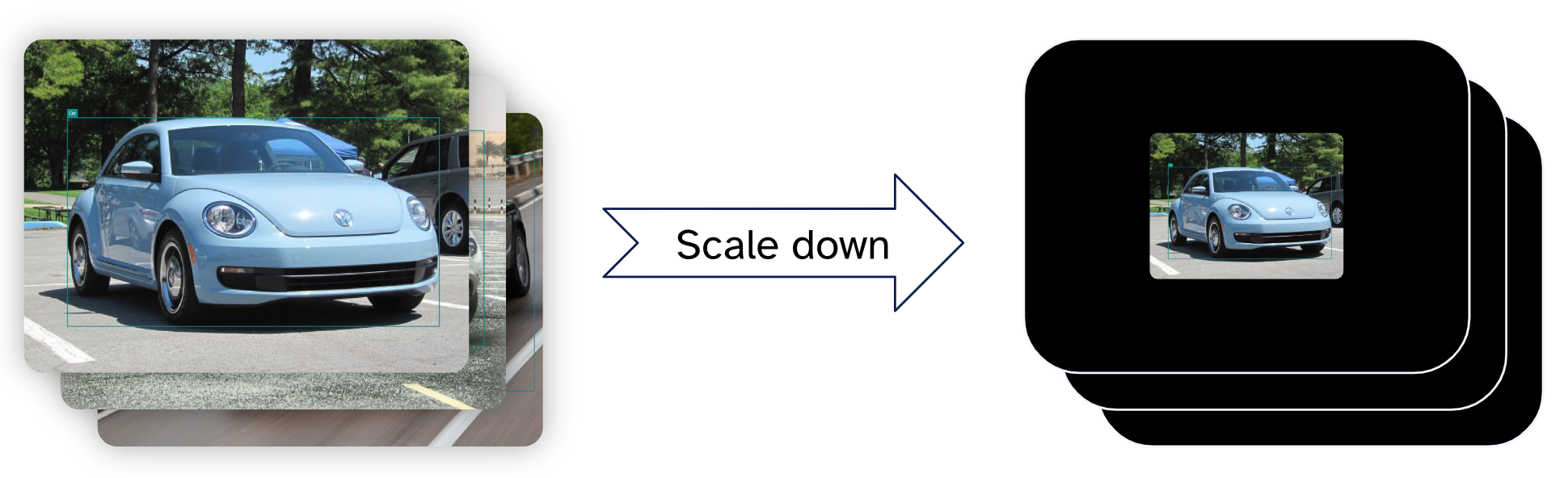
To get the training images closer to the real-world use case, the obvious way is to just shrink the images so the object is smaller relative to the new image size. When scaling down the images, the new space has to be filled in with something. The easiest way would be to just leave this area black. With our experience, we expect that the black areas in the image probably have a negative effect on the training.
Thinking about a solution for this, we thought: “Why not outpatient these areas?“
Generative Models
DALL-E, Midjourney and Stable Diffusion were some of the first models that generated images that went viral because of their realistic style. These diffusion models create images by iteratively denoising an image of initially random noise. A specific method for applying these models is inpainting. There the model gets an image, and an area of the image is specified that should be replaced. Then the model generates new content for that area that seamlessly integrates with the rest of the image. The content can also be specified by a text prompt.
So we used the open-source model Stable Diffusion to fill the black areas of the new images. Since these areas are not ‘inside’ the images but at the edges, this technique is called outpainting, though it is the same process as inpainting. Also, since we have the bounding boxes for the cars, we cut out the cars from the original images before using them for outpainting. This also makes sure that only the cars are used for the newly generated images and no other objects that may be in the background. To generate content that makes sense to surround cars, a text prompt was used that included keywords like “realistic“ and “photo“ to describe the desired style as well as the keywords describing the surroundings, like “road“, “building“, “gas station“, and “trees“. From a list of keywords, a subset was randomly selected for each image to achieve a diverse environment in the newly generated images.

Research Question: Does this lead to an improvement in model performance?
In my bachelor thesis I wanted to answer the question if the augmentation described above can improve the performance of an object detection model, especially for the detection of small objects. To answer this question, I conducted a row of experiments. I trained the same object detection model on the original Stanford Cars dataset, and datasets with varying ratios of the images of the Stanford Cars dataset were replaced with the newly generated images. In the generated images, the cars take up 10 % of the image area. This size was significantly smaller than the average relative size of the cars in the Stanford Cars dataset which was 55 %.
After training, the model’s performance was evaluated on the KITTI dataset.
What we found is that the performance metric average precision improved significantly by adding more augmented images to the training dataset. The average precision [footnote: coco metric] increased from 0.21 to a maximum of 0.35 over the augmented datasets, a 67 % improvement. Although the absolute scores seem rather low when compared to other object detectors, the focus here was on the improvement by only changing the dataset. What we also noticed is that this improvement was because the model detected more small cars.
Since some surroundings of the cars in the images were not great because they had unnatural uniform backgrounds or contained overlays with information like the source of the image, we looked into how this may be solved. For this, we came across the segment anything model (SAM) from Meta. As the name suggests, the model segments objects in images. We ran the training images through SAM to get the masks of where exactly the cars are in the image. This allows us to be more flexible in terms of generating new synthetic backgrounds without being restricted by the existing background. One crucial advantage of this is that now we are able to use images of cars in unnatural environments, like ones that are professionally made in front of a white background.
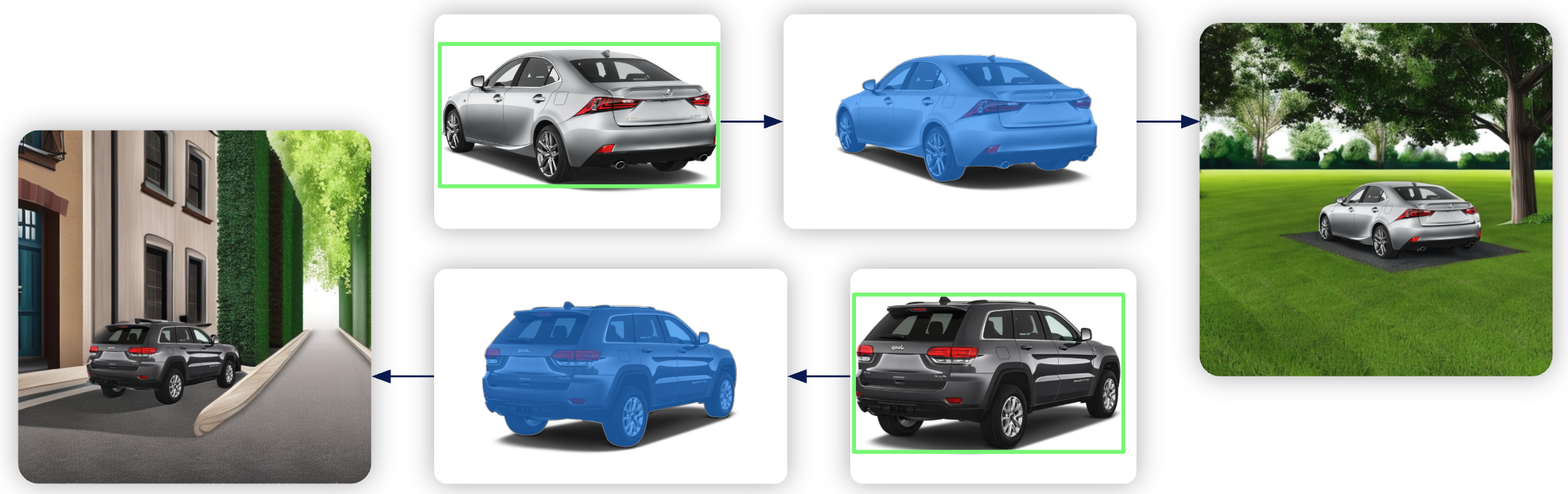
We created another row of datasets with this method and analyzed the performance. In which these training images the model improved even more to an average precision of 0.39 (from 0.21) which marks a 86 % improvement.
These experiments show that the performance of object detection models can be greatly improved by augmenting the images used for training. The use of generative models allows much more flexibility in customizing the data to be used. Here we focused on solving the problem of a difference in the size of the object in the image between training data and the use case.
Beyond Cars: Broader Applications of Semi-Artificial Data Augmentation
The success of using semi-artificial images for improving car detection highlights a versatile approach applicable to various domains facing similar data challenges. As we saw, the core idea can create more effective training datasets for diverse applications where detecting small or contextually specific objects is crucial. Let’s explore a few examples:
Medical Imaging
A critical challenge in medical imaging analysis is the detection of small, subtle anomalies—such as early-stage tumors, microaneurysms, or skin lesions—within a much larger anatomical context. While training datasets often contain clear, magnified images of these conditions, real diagnostic scenarios require clinicians or AI systems to identify these tiny indicators amidst complex backgrounds, like in a full-body CT scan or a wide-field dermatological photograph. Models trained primarily on close-up images may therefore struggle to detect smaller instances effectively when faced with broader, more realistic contexts.
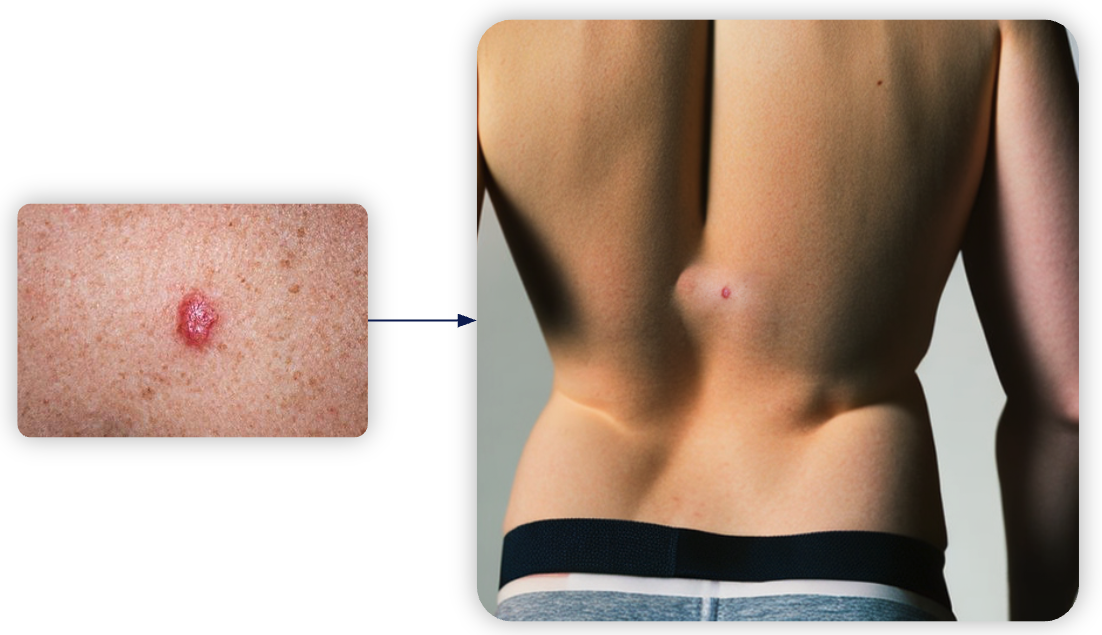
To address this, one can take a close-up image of a specific medical finding (for example, a confirmed melanoma) and use segmentation tools such as SAM to precisely isolate the lesion. Outpainting techniques can then generate a realistic anatomical background around the isolated finding, embedding the small anomaly onto a synthesized image of a larger body area—such as placing the melanoma onto a generated image of a human back. Carefully crafted prompts can guide the generation process to ensure appropriate skin texture, lighting, and scale, resulting in highly realistic composite images.
By creating these augmented training examples, we can specifically teach models to identify small lesions within a larger field of view, closely mimicking the real diagnostic challenge. This approach enriches datasets with examples of early-stage or small findings, which are often underrepresented in real-world data, and has the potential to improve the sensitivity of AI diagnostic tools for earlier and more accurate disease detection.
In the following example a close up image of a skin cancer was taken and a person was generated around it.
Manufacturing and Quality Control
Automated visual inspection plays a crucial role in manufacturing by ensuring product quality, as systems must detect often minuscule defects—such as scratches, dents, cracks, or misaligned components—on products ranging from microchips to car bodies. While training data frequently consists of images focused solely on the defect itself, real-world inspection systems are required to locate these small flaws across the much larger surfaces of actual products during production.
To bridge this gap, one can take a close-up image of a specific defect, like a scratch on a painted surface, and use segmentation techniques to precisely isolate the flaw. Outpainting can then be employed to generate the surrounding context of the product, such as reconstructing the curved panel of a car door around the scratch. Carefully designed prompts guide the generation process by specifying relevant details like the material (“car paint,“ “metallic surface“), lighting conditions (“factory lighting“), and the object in question (“car body“), resulting in realistic composite images.
This approach produces training data that explicitly presents small defects within the broader context of the product, thereby enhancing the model’s ability to perform reliably in automated quality control lines. By exposing models to examples where tiny flaws must be distinguished from normal surface variations, this method can increase inspection accuracy, reduce reliance on manual inspection, and enable earlier detection of defects in the manufacturing process.
For the following example, a close-up image of a scratch in the fender of a car was used. The model expanded the image by generating additional parts of the car.

Retail and Inventory Management
Automated systems are playing an increasingly important role in retail, handling tasks such as inventory tracking and shelf monitoring. Robots like the Ubica units tested by dm-drogerie markt in 2024 must accurately identify thousands of different products on store shelves. However, training data for these systems often consists of clean, studio-shot product images, which differ greatly from the cluttered, variably lit, and sometimes partially obscured conditions found on actual store shelves, where products may appear much smaller or be hidden behind others.
To address this challenge, standard isolated product images—such as an almond drink from the dm website—can be enhanced using outpainting techniques to generate realistic shelf environments around them. By specifying prompts like “supermarket shelf,“ “beverages section,“ and “realistic lighting,“ the target product can be placed among other synthetically generated items, effectively simulating its appearance in a real retail context.
This method enables the rapid creation of large, diverse datasets that mimic real-world shelf conditions, eliminating the need for extensive manual setup and photography for every product in every possible shelf configuration. As a result, models trained on these augmented datasets become more robust, improving their performance in automated stock counting, planogram compliance checks, and the identification of misplaced items—particularly for smaller products that are often overlooked by models trained solely on idealized product images.
Conclusion
The research presented in this blog article demonstrates the transformative potential of synthetic data augmentation for object detection, especially when tackling the persistent challenge of small object detection in real-world scenarios. By leveraging generative AI models and advanced segmentation tools, we can create semi-artificial images that bridge the gap between idealized training datasets and the complex environments encountered in practice. Our experiments show that augmenting datasets with outpainted images—where objects appear smaller and are embedded in realistic, diverse backgrounds—can significantly boost model performance, as evidenced by substantial improvements in average precision.
Beyond the automotive domain, this approach holds promise for a wide range of applications, from medical imaging and manufacturing quality control to retail inventory management. By enabling the creation of tailored, context-rich training data, synthetic augmentation empowers AI systems to better generalize and perform reliably in challenging, real-world conditions. As generative models continue to advance, the integration of synthetic data into computer vision pipelines will become an increasingly powerful and accessible tool for researchers and practitioners alike.


