
In this article we will explain how to use Airflow to orchestrate data processing applications built on Databricks beyond the provided functionality of the DatabricksSubmitRunOperator and DatabricksRunNowOperator. We will create custom Airflow operators that use the DatabricksHook to make API calls so that we can manage the entire Databricks Workspace out of Airflow. As an example use case we want to create an Airflow sensor that listens for a specific file in our storage account. When it arrives, an all-purpose cluster gets created, a couple of processing jobs are submitted and a final (small) result will be retrieved before the all-purpose cluster is terminated and deleted.
Prerequisites
We assume the reader to be familiar with the following topics:
- Python Basics incl. Object Oriented Programming and API requests.
- Airflow Basics incl. Operator Extension, Hooks, Sensors, Templating, Providers and XComs. See for instance this excellent introduction by Michal Karzynski.
- Databricks Workspace
Motivation
When building big data processing applications that work with batch data, a common technology stack is the combination of Apache Spark as the distributed processing engine and Apache Airflow as the scheduler. Spark abstracts most of the complexity involved in distributed computing while Airflow provides a powerful scheduler that allows to define complex dependencies between tasks in a Directed Acyclic Graph (DAG) with task-specific policies for retries, on failure behaviour etc. Out of the box, it also comes with a powerful monitoring UI.
When building a Spark application that runs on any major cloud platform (Azure, AWS, GCP) a natural choice for a Spark service is Databricks. Databricks describes itself as a „Unified Analytics Platform“ bringing together (Big) Data Engineering, Data Science and Business Intelligence in a single service. Although it has many features such as MLFlow integration, Delta Lake integration, interactive notebook sessions, a simple job scheduler, a REST API and more, at its core it is a managed Spark service taking care of the cumbersome process of creating and configuring multiple machines into a Spark cluster in the cloud.
Since their own scheduler is quite simple (comparable to a linux cron task) and limited to Databricks jobs only, it is not suited to orchestrate complex data pipelines that use multiple cloud services, task dependencies and task specific behavior. Therefore, Databricks also provides the Airflow plugins DatabricksSubmitRunOperator and DatabricksRunNowOperator that use its REST API to trigger Databricks jobs out of Airflow.
While the first one takes a full JSON job definition for the execution, the second one triggers an existing job in the workspace. Although this allows using Databricks in combination with Airflow it still does not cover the full spectrum of use cases that are usually covered by complex data pipelines such as: Getting small query results to be sent out via e-mail, triggering a pipeline based on an event as well as starting an all purpose cluster, executing multiple smaller jobs on it and terminating it afterwards.
For all of these use cases (and many others) we can implement custom Airflow operators that leverage the powerful Databricks API using the DatabricksHook . In this article we will describe a generic way to write custom Databricks operators and build an exemplary data pipeline of specialized custom Databricks operators that address all of the above mentioned use cases. The following figure shows the final DAG we want to arrive at.
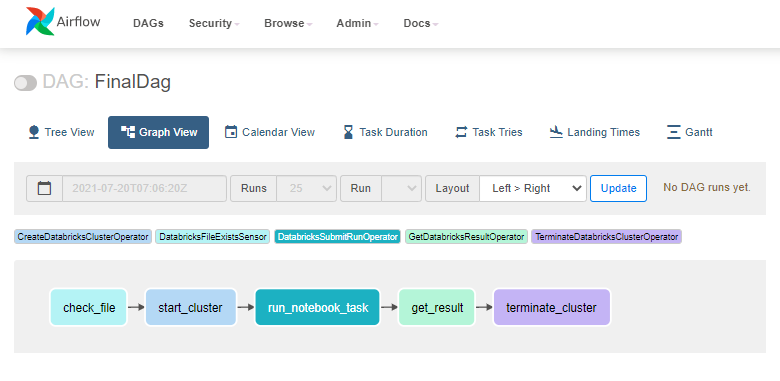
Installation
We will be using Python 3.7 from the anaconda distribution and Airflow 2.1.0 with the Databricks extension.
|
1 2 3 |
conda create -n airflow_databricks python=3.7 conda activate airflow_databricks pip install apache-airflow[databricks]==2.1.0 |
A Databricks Workspace must be set up at the cloud provider of your choice. We will use Azure Databricks (as of 07/2021) throughout this tutorial.
This should be straight forward but in case you need assistance you can find a short tutorial here.
Setup local Airflow
From the official documentation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# initialize the database airflow db init airflow users create \ --username admin \ --firstname Peter \ --lastname Parker \ --role Admin \ --email spiderman@inovex.de # ;) # start the web server, default port is 8080 airflow webserver --port 8080 # start the scheduler # open a new terminal or else run webserver with ``-D`` option to run it as a daemon airflow scheduler # visit localhost:8080 in the browser and use the admin account you just created |
This will set up airflow in your local machine’s root directory. Alternatively, you might want to adjust the AIRFLOW_HOME variable to another path: export AIRFLOW_HOME=my/path/
As another option you may use a docker container.
Authorisation
The simplest way for a given user to authorise for the Databricks API is to generate a personal access token (PAT) in the Databricks workspace using the web UI:
[ WORKSPACE_NAME ] → User Settings (in the top right corner).
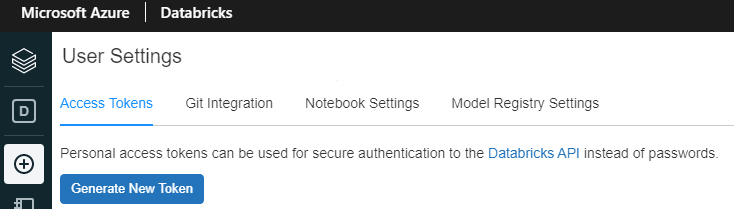
It must be stored as an Airflow connection in order to later be securely accessed.
In the Airflow UI: Admin → Connections select databricks_default and fill in the form as follows:
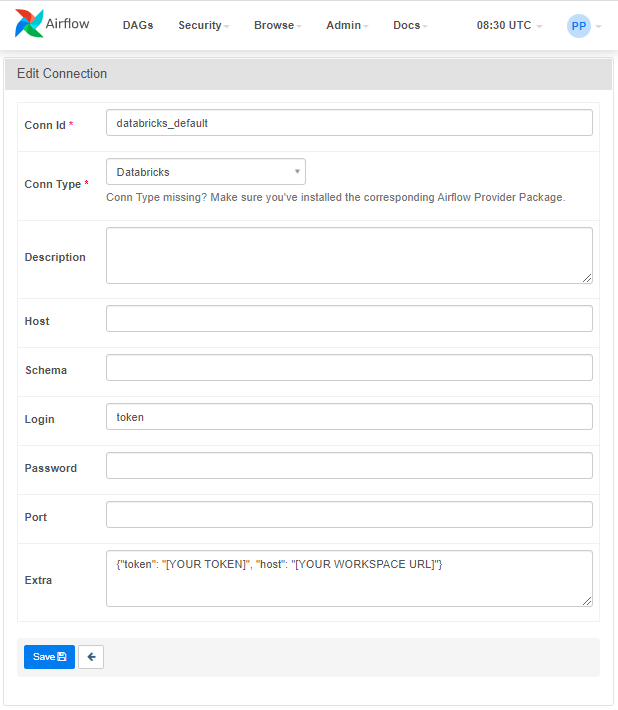
Additional connections can be added via Admin → Connections → + . Make sure to select „Databricks“ as the connection type.
Generic Databricks Operators
In order to be able to create custom operators that allow us to orchestrate Databricks, we must create an Airflow operator that inherits from Airflow’s BaseOperator class. Therefore, let’s create a new module inovex_databricks_operators.py at airflow/plugins/operators . Each custom operator must implement at least an execute() method. Additionally, one will usually implement a constructor to allow for flexible connection IDs and additional parameters. In case of our Databricks Operators we will be passing a request type, an endpoint URL and a dictionary acting as the request body for the API calls.
Have a look at the following example of a generic custom operator: The operator takes a HTTP request type (e.g. POST ) and an endpoint URL as string as well as an optional dictionary containing the request body and calls the Databricks API. Additional BaseOperator arguments can be passed as keyword arguments.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import json from typing import Dict, Optional from airflow.models import BaseOperator from airflow.providers.databricks.hooks.databricks import DatabricksHook class GenericDatabricksOperator(BaseOperator): template_fields = ("request_body",) def __init__( self, request_type: str, endpoint: str, request_body: Optional[Dict] = None, databricks_conn_id: str = "databricks_default", **kwargs, ): super().__init__(**kwargs) self.request_type = request_type self.endpoint = endpoint self.request_body = request_body or {} self.databricks_conn_id = databricks_conn_id def execute(self, context): databricks_hook = DatabricksHook(databricks_conn_id=self.databricks_conn_id) self.log.info("Submitting %s to %s " % (self.request_type, self.endpoint)) responds = databricks_hook._do_api_call( (self.request_type, self.endpoint), self.request_body ) self.log.info("Responds:") self.log.info(json.dumps(responds)) return responds |
Inside the execute() method, we create an instance of the DatabricksHook using the Databricks connection ID.
The hook has a _do_api_call() method which retrieves the credentials from the Airflow connection and makes API calls to Databricks using Python’s built-in request package.
The method takes two required arguments to build the request:
- A tuple of strings containing the HTTP request type (e.g. "POST" , "GET" ) and the API endpoint (starting with "api/2.0/" )
- A dictionary containing the request body asked for. Since this is a templated field the request body can contain Airflow macros that will be rendered by the operator.
You can find the required parameters for each possible API call in the Databricks API documentation. Note that _do_api_call by convention is a protected method.
This is basically it. With this Operator you can build very flexible Databricks data pipelines.
As an example, see the following DAG with a single task that starts an existing cluster.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from datetime import datetime from inovex_databricks_operators import GenericDatabricksOperator from airflow import DAG default_args = {"owner": "inovex", "retries": 0, "start_date": datetime(2021, 1, 1)} with DAG("GenericExample", schedule_interval=None, default_args=default_args) as dag: # lets start an all_purpose cluster we have already created manually given its id. # We get the request structure from: # https://docs.databricks.com/dev-tools/api/latest/clusters.html#start start_existing_cluster = GenericDatabricksOperator( task_id="start_existing_cluster", request_type="POST", endpoint="api/2.0/clusters/start", request_body={"cluster_id": "YOUR-CLUSTER-ID"}, do_xcom_push=True, # this way we could process the response in another task ) |
Next, let’s have a look at some use cases for which we will create specialized Operators.
Implementations for Specific Use Cases
Getting Query Results
Querying a table e.g. for sending the result to some user for reporting or monitoring via E-Mail is a common task in many ETL workflows. This use case requires extracting some return value from Databricks into Airflow so that it can be sent out using the EmailOperator .
Via the Databricks Job API, the results returned from the job run of a notebook can be retrieved by using the 2.0/jobs/runs/get-output endpoint. The request must specify the run ID of the executed job. Values to be returned are passed to dbutils.notebook.exit() as a string at the end of the Databricks notebook.
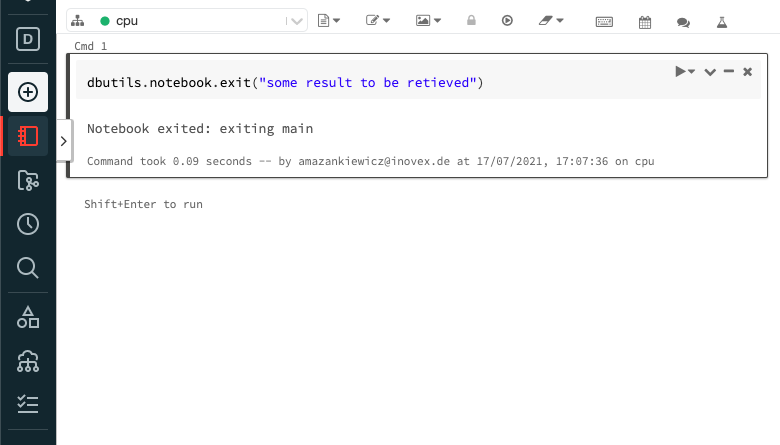
As you can see in the code snippet below, we construct the GetDatabricksResultOperator with a connection ID for Databricks and the task ID of a specific DatabricksRunNowOperator or DatabricksSubmitRunOperator task instance. Make sure that the task pushes the run ID to xcom by setting the run operator’s do_xcom_push parameter to True .
On execution, we retrieve the run ID of the specified task from xcom. We then inject that run_id into the endpoint and execute the API call. From the response we retrieve the result and push it to xcom and thereby make it accessible to other tasks in a DAG (e.g. to an instance of the E-Mail operator).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from airflow.models import BaseOperator from airflow.providers.databricks.hooks.databricks import DatabricksHook class GetDatabricksResultOperator(BaseOperator): def __init__( self, run_task_id: str, databricks_conn_id: str = "databricks_default", **kwargs ): super().__init__(**kwargs) self.run_task_id = run_task_id self.databricks_conn_id = databricks_conn_id def execute(self, context): databricks_hook = DatabricksHook(databricks_conn_id=self.databricks_conn_id) run_id = context["task_instance"].xcom_pull(self.run_task_id, key="run_id") responds = databricks_hook._do_api_call( ("GET", f"api/2.0/jobs/runs/get-output?run_id={run_id}"), {} ) result = responds["notebook_output"]["result"] self.log.info("Result:") self.log.info(result) return result |
Triggering a Pipeline Based on an Event
It is common to trigger a workflow on the occurrence of an external event, e.g. the emergence of a _SUCCESS file in a storage bucket. While we could use some serverless cloud function service for that, it requires us to have this additional service available and configured, adds this additional dependency to the application and makes it less platform agnostic. A simple alternative would be an Airflow sensor that listens for a file at a specified path and triggers the respective jobs.
Our DatabricksFileExistsSensor inherits from Airflow’s BaseSensorOperator and is initialized with a file path. On poke() , a request is sent to the 2.0/dbfs/get-status endpoint, the body containing that file path.
With the API call throwing an exception if the specified path does not exist, we need to catch the exception with the error code “RESOURCE_DOES_NOT_EXIST” and continue poking by returning False . When the request is successful i.e. not throwing the exception, we complete the task by returning True .
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
from airflow.exceptions import AirflowException from airflow.providers.databricks.hooks.databricks import DatabricksHook from airflow.sensors.base import BaseSensorOperator class DatabricksFileExistsSensor(BaseSensorOperator): def __init__( self, file_path: str, databricks_conn_id: str = "databricks_default", **kwargs ): super().__init__(**kwargs) self.file_path = file_path self.databricks_conn_id = databricks_conn_id def poke(self, context): databricks_hook = DatabricksHook(databricks_conn_id=self.databricks_conn_id) try: databricks_hook._do_api_call( ("GET", "api/2.0/dbfs/get-status"), {"path": self.file_path} ) self.log.info("File %s found" % self.file_path) return True except AirflowException as e: print(e) if '"error_code":"RESOURCE_DOES_NOT_EXIST"' in str(e): self.log.info("No file found at %s" % self.file_path) else: raise e return False |
Starting All Purpose Cluster, Execute Jobs and Terminate
Last but not least, using the provided Databricks operators as they are for job execution has a fundamental drawback. Each Airflow task is executed as an individual Databricks job. In Databricks, each job either starts and shutdowns a new job cluster or uses a predefined all-purpose cluster (identified by its ID in the job definition). Considering a workflow composed of many small jobs that run for 1 or 2 minutes each, the overhead of creating and deleting the job clusters between each of the tasks is disproportionately high compared to the jobs’ execution times. On the other hand, using an all-purpose cluster requires manually creating that cluster and injecting the cluster id to the job definitions. The termination of the cluster would have to be managed manually or by an auto termination configuration (which will, more often than not, be set too long or too short and thus be wasteful).
All of this is not satisfying for the efficient automation of complex workflows. What we would like to have instead, is a way of starting a defined all-purpose cluster automatically at the beginning of the DAG, execute all jobs and finally terminate and delete it.
Note that using an all-purpose cluster instead of a job cluster is approx. 4x more expensive in terms of Databricks Units. There is a somewhat indirect way to also run multiple jobs on one job cluster but that deserves its own blog post.
The
CreateDatabricksClusterOperator is used to create and start a Databricks all-purpose cluster according to a given specification. The API request to the endpoint
2.0/clusters/create returns the cluster’s ID, which we push to xcom for future reference.
To make sure that the cluster is in a running state after the execution of our operator, we keep requesting the cluster’s state using the
2.0/clusters/get endpoint every 10 seconds until the returned
cluster_status is
RUNNING . In addition, we define an
on_kill() method that makes sure the cluster is being shut down if the task gets interrupted prior to finishing.
Once the task succeeds, any existing or new job can be executed on the running cluster using the DatabricksSubmitRunOperator or the DatabricksRunNowOperator . We only need to retrieve the cluster id from xcom (as demonstrated in the final DAG).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
from time import sleep from typing import Dict from airflow.exceptions import AirflowException from airflow.models import BaseOperator from airflow.providers.databricks.hooks.databricks import DatabricksHook class CreateDatabricksClusterOperator(BaseOperator): template_fields = ("request_body",) def __init__( self, request_body: Dict, databricks_conn_id: str = "databricks_default", **kwargs, ): super().__init__(**kwargs) self.request_body = request_body self.databricks_conn_id = databricks_conn_id self.databricks_hook = None self.cluster_id = None def execute(self, context): self.databricks_hook = DatabricksHook( databricks_conn_id=self.databricks_conn_id ) responds = self.databricks_hook._do_api_call( ("POST", "api/2.0/clusters/create"), self.request_body ) self.cluster_id = responds["cluster_id"] self._sleep_until_created() context["task_instance"].xcom_push("all_purpose_cluster_id", self.cluster_id) def _sleep_until_created(self): self.log.info("Waiting until cluster %s is created" % self.cluster_id) while True: cluster_status_responds = self.databricks_hook._do_api_call( ("GET", f"api/2.0/clusters/get?cluster_id={self.cluster_id}"), {} ) cluster_status = cluster_status_responds["state"] if cluster_status not in ("PENDING", "RUNNING"): raise AirflowException( f"Cluster status of {self.cluster_id} is neither 'PENDING' nor 'RUNNING'. It's {cluster_status}" ) if cluster_status == "RUNNING": self.log.info("Cluster %s created" % self.cluster_id) break sleep(10) def on_kill(self): self.databricks_hook._do_api_call( ("POST", "api/2.0/clusters/permanent-delete"), {"cluster_id": self.cluster_id}, ) self.log.info("Cluster %s killed" % self.cluster_id) |
The TerminateDatabricksClusterOperator allows us to shut down a specific cluster via the 2.0/clusters/permanent-delete endpoint, irrespective of whether or not the upstream job execution tasks resulted in success or error. This behavior is enforced by setting the operator’s trigger rule to "all_done" (instead of "all_success" ).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
from airflow.models import BaseOperator from airflow.providers.databricks.hooks.databricks import DatabricksHook class TerminateDatabricksClusterOperator(BaseOperator): def __init__( self, create_cluster_task_id: str, databricks_conn_id: str = "databricks_default", trigger_rule: str = "all_done", # we want to make sure the cluster is deleted in any case **kwargs, ): super().__init__(trigger_rule=trigger_rule, **kwargs) self.create_cluster_task_id = create_cluster_task_id self.databricks_conn_id = databricks_conn_id def execute(self, context): cluster_id = context["task_instance"].xcom_pull( self.create_cluster_task_id, key="all_purpose_cluster_id" ) databricks_hook = DatabricksHook(databricks_conn_id=self.databricks_conn_id) databricks_hook._do_api_call( ("POST", "api/2.0/clusters/permanent-delete"), {"cluster_id": cluster_id} ) self.log.info("Cluster %s terminated" % cluster_id) |
Final DAG
Our final example DAG is a sequence of the custom airflow operators:
- File sensor: The sensor listens for a given file path in the DBFS and finishes when the requested file (created by another external process) exists.
- Start cluster: Using the CreateDatabricksClusterOperator we set up a cluster and wait for it to be running.
- Execute job: We submit and run a job in Databricks using the DatabricksSubmitRunOperator . In the request body we provide as the existing_cluster_id the Airflow macro "{{ti.xcom_pull('start_cluster', key='all_purpose_cluster_id')}}" causing the operator to retrieve the cluster ID of our all-purpose cluster from xcom. In this case, start_cluster is the task_id of the CreateDatabricksClusterOperator task that created the cluster and all_purpose_cluster_id is the key under which the Operator pushed the cluster_id onto xcom.
- Get result: The value returned by the executed notebook is obtained using the GetDatabricksResultOperator and the result is pushed to xcom for later use (e.g. by an E-Mail Operator).
- Terminate cluster: Regardless of the state in which 3. and 4. finished, the Databricks cluster is being shut down and deleted.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
from datetime import datetime from custom_databricks_operators import ( CreateDatabricksClusterOperator, DatabricksFileExistsSensor, GetDatabricksResultOperator, TerminateDatabricksClusterOperator, ) from airflow import DAG from airflow.providers.databricks.operators.databricks import ( DatabricksSubmitRunOperator, ) default_args = {"owner": "inovex", "retries": 0, "start_date": datetime(2021, 1, 1)} with DAG("FinalDag", schedule_interval=None, default_args=default_args) as dag: wait_for_file = DatabricksFileExistsSensor( task_id="check_file", file_path="/tmp.parquet/_SUCCESS" ) # https://docs.databricks.com/dev-tools/api/latest/clusters.html#create create_request = { "cluster_name": "airflow_cluster", "spark_version": "7.3.x-scala2.12", "node_type_id": "Standard_DS3_v2", "num_workers": 1, } # NOTE: subject to all-purpose databricks pricing! start_cluster = CreateDatabricksClusterOperator( task_id="start_cluster", request_body=create_request ) # https://docs.databricks.com/dev-tools/api/latest/jobs.html#runs-submit submit_job_request = { "existing_cluster_id": "{{ti.xcom_pull('start_cluster', key='all_purpose_cluster_id')}}", "notebook_task": {"notebook_path": "/Shared/main"}, } run_notebook_task = DatabricksSubmitRunOperator( task_id="run_notebook_task", json=submit_job_request, do_xcom_push=True ) # run_task_id = task_id from DatabricksSubmitRunOperator get_result = GetDatabricksResultOperator( task_id="get_result", run_task_id="run_notebook_task" ) # create_cluster_task_id = task_id from CreateDatabricksClusterOperator terminate_cluster = TerminateDatabricksClusterOperator( task_id="terminate_cluster", create_cluster_task_id="start_cluster" ) wait_for_file >> start_cluster >> run_notebook_task >> get_result >> terminate_cluster |



Hi there, this article is so great but databricsk has evolved since then a lot of features have been added , it would be nice if you do an updated version