
Batch processing of data can be significantly more cost-effective, as requests are handled together with consistent resource utilization – this is especially useful for prompt batch processing with LLMs, as mostly costly GPU resources are required.
In contrast, processing individual prompts on the fly can create an inefficient usage pattern – periods of high demand alternate with idle time when no requests are being processed, yet infrastructure costs remain constant regardless of utilization.
While providers like OpenAI offer a Batch API for processing many prompts at once, the goal of this article is to showcase how this is possible with Open Source models and Open Source technologies potentially hosted on private infrastructure to also make this capability available for projects where compliance regulations do not allow otherwise.
Many clients prioritize the secure processing of their data, especially when utilizing technologies like large language models (LLMs). By hosting open-source models in a private data infrastructure, companies can ensure that their data remains within their private infrastructure, significantly enhancing their compliance posture.
Another advantage of hosting open-source technology is the flexibility and customizability when implementing the solution in terms of the business needs, for example, when trying out different open source models.
For those scenarios where LLM batch GPU-efficient processing and the aforementioned privacy restrictions play a role Ray and its ecosystem can be a very good choice, as we will see in the next sections.
Ray Overview
In their own words, Ray is described as “an open-source framework to build and scale your ML and Python applications easily“. Prominent companies such as Spotify, OpenAI and Amazon have already established parts of their machine learning platforms on Ray, showcasing its reliability in real-world applications. At the start, the Ray ecosystem might be overwhelming with all its different sub-projects. The good news is that for building such an LLM Batch Service (scope of this blog post), we mostly care about Ray Data, which targets the distributed and scalable processing of Datasets. This includes loading data from an external storage system and then feeding it into an ML model – in our case, this will be a LLM as we will see later.
Ray’s mission statement from before also mentioned scalability. This can be achieved by the Kubernetes operator called KubeRay. This integration with Kubernetes allows organizations to dynamically adjust their resources based on workload demands, ensuring optimal performance and cost-efficiency. As LLMs can be GPU-intensive, this feature is invaluable for managing computational resources effectively.
Additionally Ray is deeply rooted in the Python machine learning ecosystem, making it compatible with popular libraries such as TensorFlow, PyTorch (since Oct, 2025 Ray is part of the PyTorch Foundation, bringing the projects even closer together), HuggingFace – and most relevant for this blog post: vLLM. This integration enables developers to create powerful LLM applications tailored to their specific needs while leveraging existing tools and frameworks, enhancing productivity and innovation.
LLM Batch Inference with vLLM on Ray
vLLM
vLLM is a popular choice for serving LLMs. With a simple command like vllm serve meta-llama/Meta-Llama-3.1-8B-Instruct you can spin up a fully OpenAI API-compatible instance to serve your requests.
While it also offers a batch entry point, where you can reference a .jsonl file for multiple prompts, it does not expose a REST interface
Also, it does not offer an advanced scalability and hardware allocation mechanism like Ray. In fact, vLLM recommends using Ray in such cases.
Ray & Problem statement
Our problem statement is to feed a corpus of independent prompts into our LLM and receive an output. Hence, it boils down to a data parallelism problem.
Meaning: We can theoretically scale our execution time for the batch inference linearly depending on the amount of input prompts. In the extreme, this would mean having one dedicated GPU for one prompt. But this would definitely not be efficient in any way. Hence, we rather feed in the input prompts in smaller batches so that every GPU can process a certain amount of it.
-
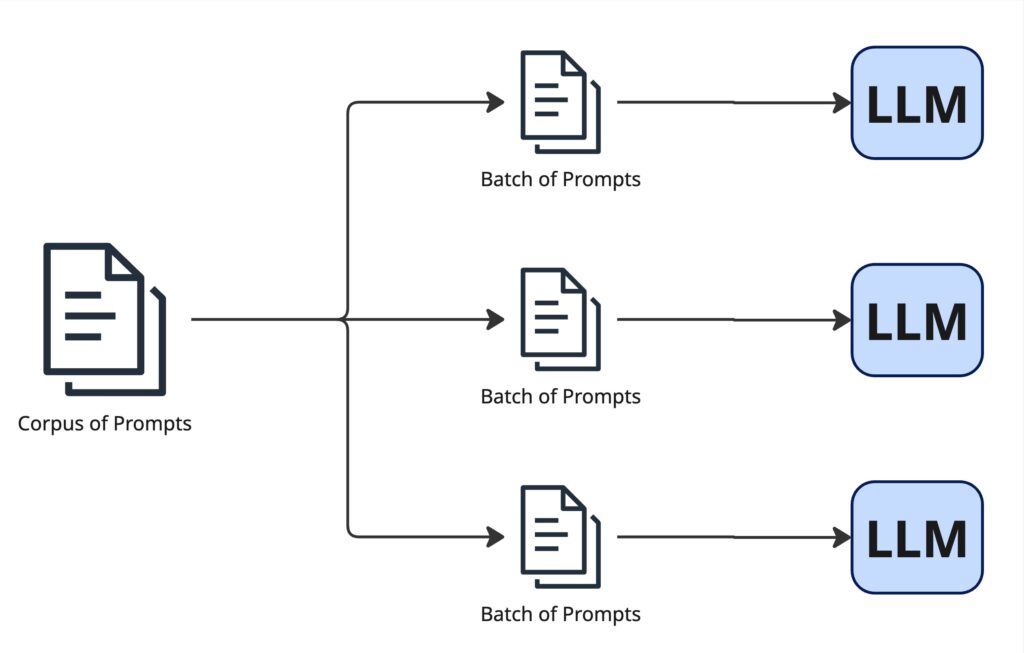
Fig. 1. To utilize our costly GPU Hardware where our LLM is running on we need to submit batches of prompts.
This is where Ray supports us with its concepts and also represents how a Ray Cluster (see Fig. 2.) is built up in general.
-
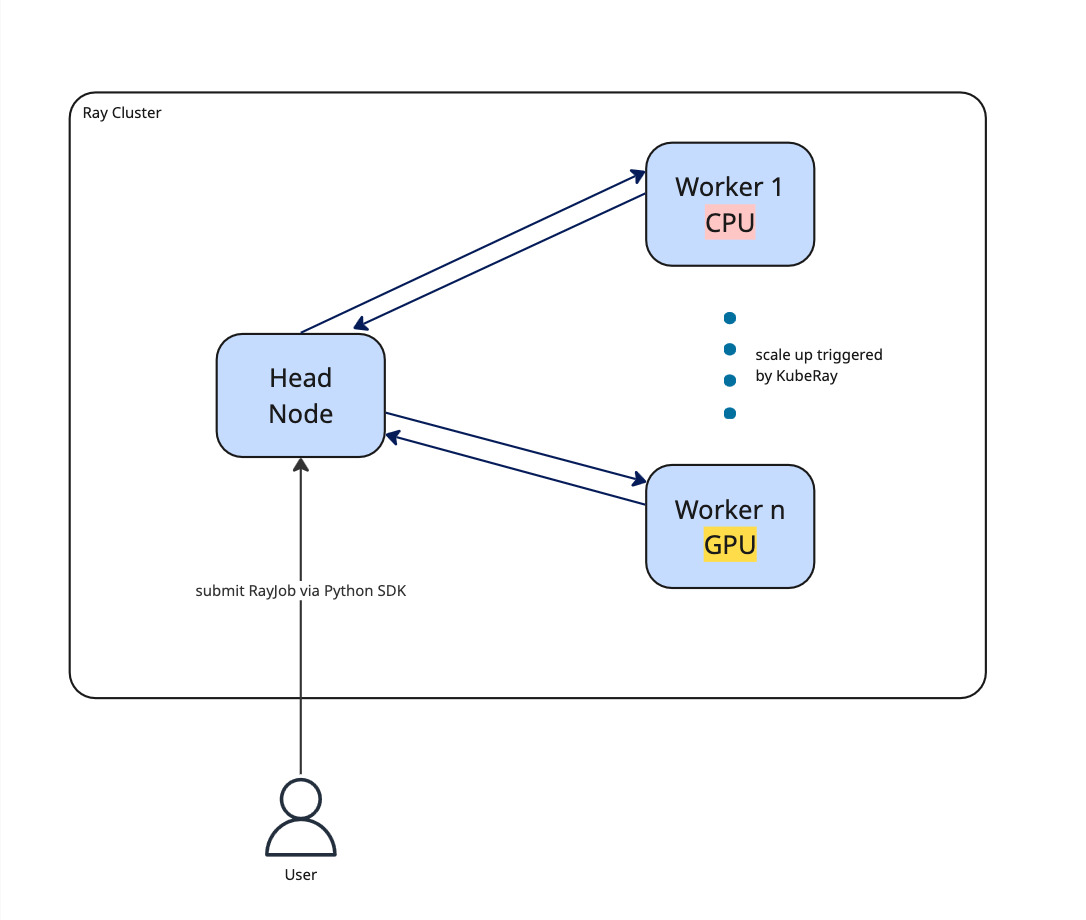
Fig. 2. The Ray Cluster architecture with different worker types (CPU/GPU). Note: This is still a very simplified representation of the Ray cluster. For example, those different workers can live either on the same Kubernetes Pod or on different ones.
As a distributed system, Ray has a head node, which coordinates the job execution and is the entry point for submitting jobs to the Ray cluster. Apart from the head, there are 0-N worker nodes. So in its simplest form, a Ray cluster can consist of only the Ray head, which then also does the actual job computation. Depending on the workload, more workers will be spawned. One can be very specific about defining those specific hardware resources. For instance, you can require that your workload should run on a hardware type that has any sort of GPU (fractional GPUs are also possible). However, it is also possible to be much more specific by referencing a particular GPU family like NVIDIA_TESLA_V100. This is particularly useful, as vLLM and HuggingFace sometimes give particular advice on what hardware they recommend to run the LLMs on.
In that way you can define worker group specifications via KubeRay (for a snippet of what that looks like for a GPU worker group, see Fig. 3), which act like blueprints/templates and specify what the concrete hardware the Ray-worker Kubernetes pod should be provisioned onto should look like.
For running the batch inference via vLLM on Ray, ray.data provides some valuable abstractions, which facilitate tackling such a use case by a great factor (see Box 1).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import ray from ray.data.llm import vLLMEngineProcessorConfig, build_llm_processor config = vLLMEngineProcessorConfig( model_source="meta-llama/Meta-Llama-3.1-8B-Instruct", engine_kwargs=dict( enable_prefix_caching=True, enable_chunked_prefill=True, max_num_batched_tokens=4096, ), concurrency=4, accelerator_type=NVIDIA_TESLA_V100, batch_size=64, ) processor = build_llm_processor( config, preprocess=lambda row: dict( messages=[ {"role": "system", "content": "You summarize inovex blog posts"}, {"role": "user", "content": f"Summarize the following blog and extract its key points in a few sentences {row['blog_content']} "}, ], sampling_params=dict( temperature=0.3, max_tokens=20, detokenize=False, ), ), postprocess=lambda row: dict( resp=row["generated_text"], ), ) ds = ray.data.read_json(paths="blog_posts.jsonl", filesystem=fs) # fs is your PyArrow filesystem ds = processor(ds) for row in ds.take_all(): print(row) |
Box 1. Ray Data gives us useful abstractions for implementing the use case of offline batch inference via vLLM.
config(line 4): This config sets up everything that we would usually also pass into vLLM – from the obvious model_source to options like enable_prefix_caching. Indeed, this is fully compatible with the vLLM engine, so every other option can be passed in here.Additionally we can specify
concurrency=4(line 11). In this case the KubeRay Autoscaler will then “order“ four Ray worker nodes – each with a NVIDIA V100 GPU – from Kubernetes. Each worker node will then launch one replica of the specified vLLM engine process. Of course, after the vLLM processing is done, the KubeRay Autoscaler will shut down those resources again so that the costly GPU hardware is only up for as long as required.
batch_size(line 13) corresponds to the number of prompts we are feeding into each vLLM engine process. The goal with that is to achieve a good balance between fully utilizing the GPU resource but not overloading it at the same time. This, of course, heavily depends on the model and GPU combination for your use case and might require some experimentation.For more information on the config object, see here.
build_llm_processor(line 15) allows us to (optionally) do some pre- and post-processing of the prompts/output. It is important that the input data has amessagesfield in the OpenAI chat format, so that the vLLM process can operate on it.
Note: This is still a very minimalistic example, which does not take into account the more complex JSONL structure of the official OpenAI specification. For conciseness, this is not done within this blog post.
Ray Data offers multiple integrations for loading data into the Ray Cluster as a distributed dataset. Also, there is support for directly loading JSONL data, which is used by the OpenAI Batch API to specify multiple prompts in one file, with which a batch job can be initiated. It is very flexible, as you can provide it with any PyArrow filesystem (S3, Blob storage, GCS, …). From there on, Ray data will take care of feeding the right amount of data specified by batch_size into the vLLM process(es) (see Box 1).
If you still want to do custom distributed pre-processing on your dataset before loading it into your vLLM, you can choose from many “general purpose“ functions from the DataSet API.
This is a thing that I really appreciate regarding the ray.data APIs: the heavy lifting is abstracted away from the programmer. By having basic building blocks for mapping/filtering/… your Dataframe you have a very concise yet powerful toolbox at hand to solve hard distributed data processing. If you know Apache Spark, you might recognize a huge resemblance here! Indeed, some data teams already shifted their data processing part away from Spark towards ray-data.
With those basic building blocks, you could achieve everything that vLLMEngineProcessorConfig and build_llm_processor (see Box 1) do with only a bit more code. So those higher abstractions are just “syntax sugar“ over those basic building blocks, as the Ray team discovered that so many people are using vLLM within their Ray Data processes, and hence it was a great idea to make it even more approachable with those higher abstractions.
While this blog posts focuses on a very specific part, which is batch LLM inference, you can think about different use cases in which you could further process the data with Ray. For example, you could also process the output data of those LLMs, enhance it with some user data, save it to another database, and then continue the processing. Think ETL: All those results can be used to feed it to other processes down the pipeline.
And such a workflow can greatly benefit from the worker group specifications that we already mentioned (and which you can see in more detail in Fig. 3): In the first step of loading data, you might want to use a very CPU-intensive worker group, while the LLM stage can then be tackled by a more GPU-heavy worker group.
-
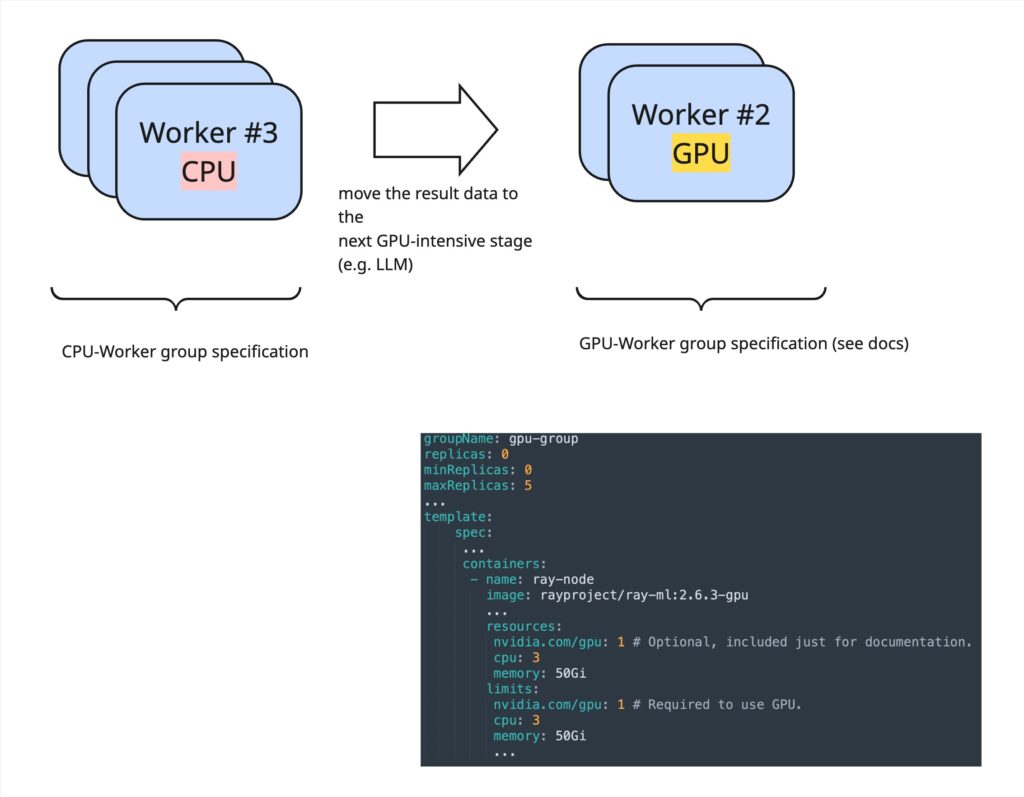
Fig. 3. Ray worker groups with different specifications (CPU/GPU) and the corresponding KubeRay specification.
Architecture
While the last section gave an overview of how Ray & vLLM can be used to implement the core functionality of LLM Batch Inference, this chapter gives an overview of a potential architecture which can be used to implement the OpenAI HTTP Batch specification, so that it can be used with official client libraries, as if we were interacting with OpenAI APIs.
Because up to this point it is offline inference at its best (or worst for that matter 🙂): We don’t expose that capability yet to the outside world as a HTTP interface.
For that, we need a HTTP server, which implements the endpoints from the OpenAI Batch API – for example via FastAPI.
That service handles JSONL uploads from the clients and saves that on some external storage system, where later the Ray Job can pick it up from (for the whole architecture see Fig. 4).
For tracking the various file uploads and the corresponding job statuses a SQL database also comes in handy.
With this information the FastAPI app can eventually submit a RayJob via the Python SDK to our Ray Cluster. At its core this Ray job does exactly what we showcased in the last section: Processing the prompts via vLLM.
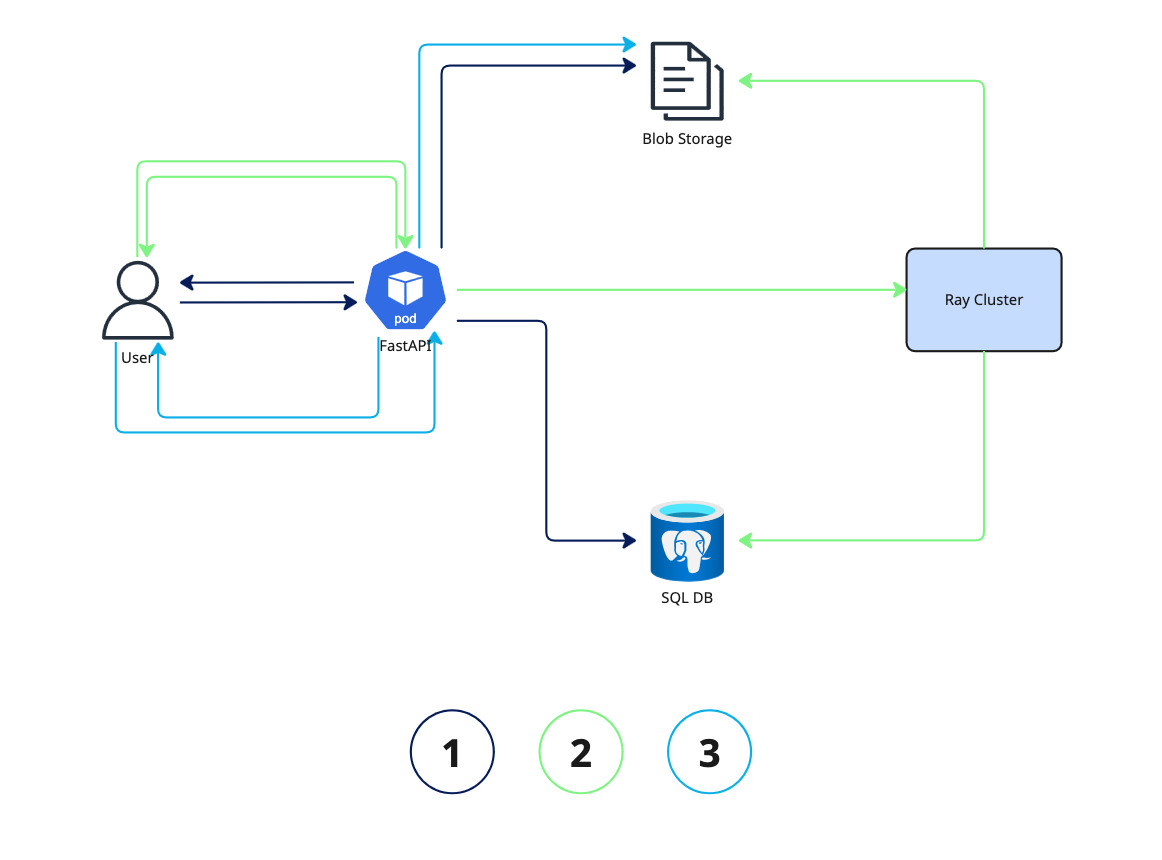
/files endpoint, which returns a file-id to the user. The FastAPI service will process the data, do some validation and then save it on blob storage as well as on the SQL DB, for referencing it for further processing. 2.) The user initiates the batch job by calling the /batches endpoint which includes the file-id from the previous step. With that information the Ray process will load the jsonl data from the blob storage and start processing the prompts on vLLM. 3.) The user polls on the job-id. Once the job finished, ray will store the results on blob storage and the FastAPI service will serve it to the user.
-
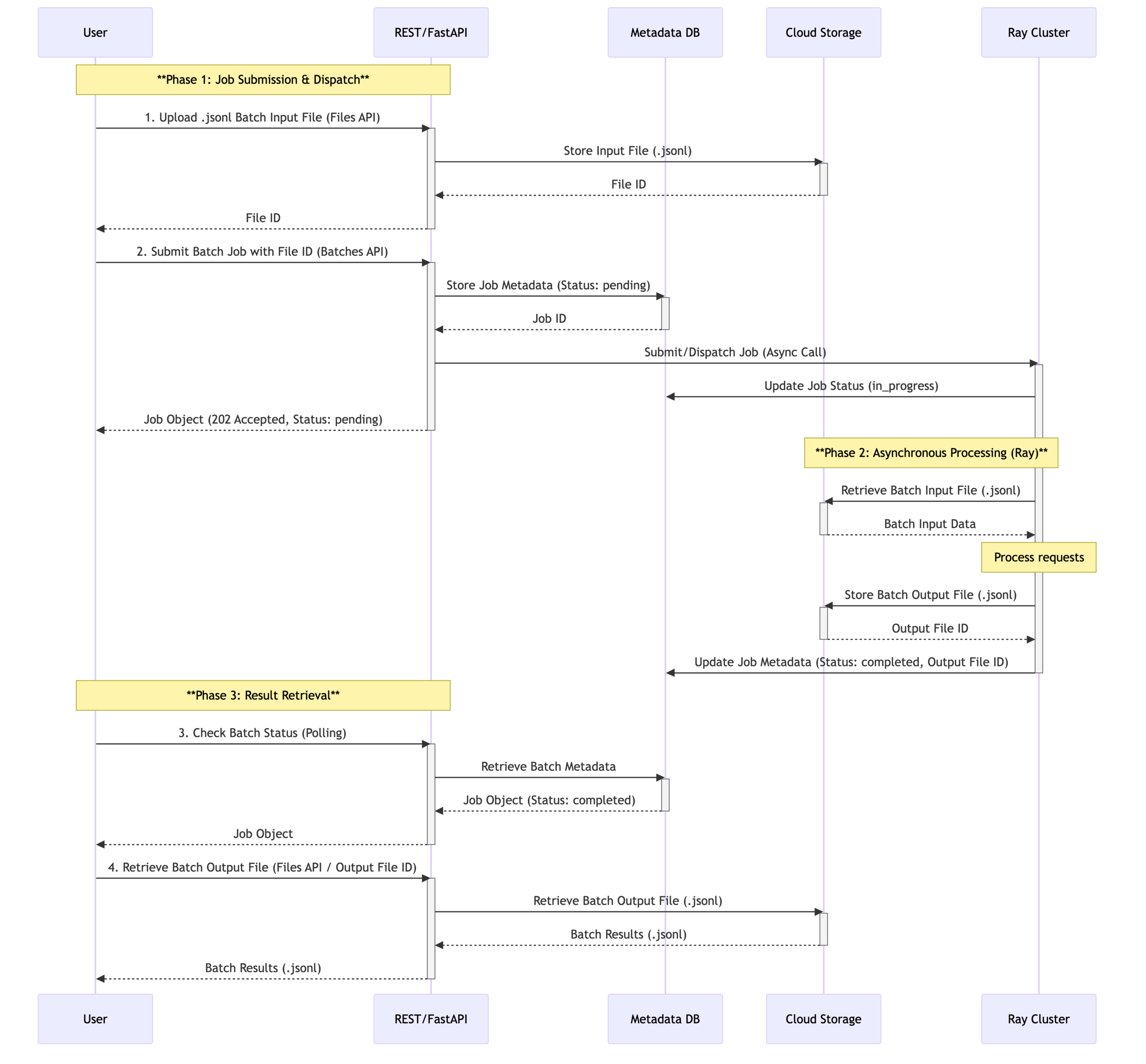
Fig. 5. Close-up sequence diagram
Besides the GPU-intensive vLLM workload, we can, of course, also execute arbitrary Python code – in this case, the Ray process shall also store its output on our cloud storage, as well as updating the job status in the SQL database.
For those additional library dependencies, Ray supports various ways of getting them into the cluster (uv, conda, …)
This Batch API can especially be beneficial in your overall data architecture, if you also provide “live LLM APIs“ – that operate 24/7 – as the Batch API can take over load from use cases that need to process thousands of documents in an asynchronous manner. If documents were instead submitted to the live LLM APIs, it could slow it down and, in consequence, distribute the user experience when using systems like your company’s Chat UI, where smooth synchronous message exchange between the user and LLM is crucial.
Summary & Challenges
That’s it! We’ve seen how we can achieve a cost-effective, fully OpenAI compatible Batch API service with Ray and vLLM hosted on our own infrastructure!
Ray makes it quite straightforward to solve such problems with its code abstractions & concepts: loading the data from various storage systems and configuring the LLM to run on GPU hardware. However, there were some parts where the learning curve felt quite steep. For example, when using vLLM code directly within a Ray process – to further customize the LLMs behavior (no example for this is given within this blog post to not blow the scope). While there is the Ray Debugger, it is still not quite easy to drill into a bug on that level. Although, this holds true for most of my debugging experience with distributed systems. Ray is actively monitoring the needs of the bigger ML community/landscape and integrates new trends quickly into one of its sub-libraries, which is great. By that, Ray versions are released frequently with crucial updates, to catch up with the fast pace of the GenAI landscape – so be sure to have a strong foundation to cope with updating those dependencies often.
So in summary, if you are searching for an Open Source platform to build your ML platform on, Ray might be what you are looking for.



