
TL;DR:
The essentials of Agentic Workflows and MCP for building a coding assistant
What are Agentic Workflows and MCP?
Agentic Workflows let AI agents operate autonomously, but within controlled, well-defined workflows. MCP standardizes how AI communicates with external tools like GitLab.
Benefits
- Controlled Autonomy: Agents act independently, but only within safe boundaries
- Modularity & Extensibility: Subgraphs keep workflows organized and easy to update
- Easy Tool Integration: MCP allows seamless connection to new tools
Use Cases
- Code Q&A: Answering questions about code
- Code Revision: Detecting and fixing errors, adding features or docstrings
- GitLab Automation: Managing project resources
Key Challenges
- Prompt Sensitivity: Small prompt changes can have a large impact on outcomes
- Non-Determinism: Makes testing and orchestration harder
- Resource Demands: Many model and tool calls increase costs
- Security: Strict access and observability is essential
Areas of Improvement
- Context Engineering: Use different strategies and methods to improve context
- More Human-in-the-Loop: Increase user feedback for more control
- Comprehensive Testing: Catch errors early and reliably
Conclusion
Agentic Workflows and MCP enable secure, flexible coding assistants for GitLab – however, success depends on balancing autonomy, control, and ongoing optimization.
LangGraph enables us to create and orchestrate workflows driven by Large Language Models (LLMs).
In this article, we share our lessons learned from working with Agentic Workflows and Model Context Protocol (MCP) by using a respective GitLab server.
What Are Agentic Workflows?
Agentic Workflows are a new paradigm in Artificial Intelligence (AI) automation. They promise more flexible, adaptive processes by leveraging the capabilities of autonomous agents while still maintaining structure and oversight. But what exactly makes them different from pure agents, and why are they gaining so much attention?
Why Don’t We Use Pure Agents?
Agents represent autonomous systems where the AI doesn’t just execute predefined tasks, but independently pursues self-defined goals – often using various tools. By analyzing situations, making decisions, and dynamically adapting their actions, agents can refine their results.
In theory, of course, this sounds wonderfully simple, but this autonomy brings challenges. How do we prevent agents from performing unwanted actions, especially when they have write access, meaning that they could potentially manipulate resources and code in production or delete important information or credentials? And how do we maintain oversight of their decisions? The more autonomy we allow, the less control and transparency we retain.
The solution: We give agents a defined framework in which they can operate. Thus, we create Agentic Workflows that balance autonomy with control.
How Agentic Workflows Are Created
To create Agentic Workflows, we use the framework LangGraph. It defines models, functions, and tools as nodes in a graph, more precisely a Directed Acyclic Graph (DAG).
The edges connecting the nodes describe the paths that the agent can take from one node to another. There are generally two types of edges: unconditional and conditional. Unconditional edges always lead from one node to a specific next node after processing. Conditional edges, on the other hand, mean that multiple edges stem from a single node. The system then decides which edge to follow based on a particular condition. This allows for different paths depending on the outcome. Additionally, the conditions enable us to control when the agent has access to a processing step.
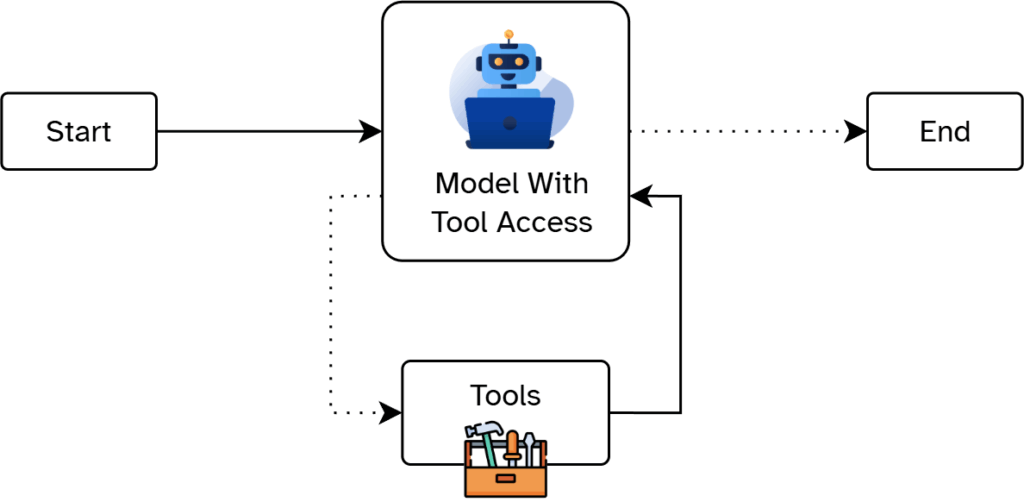
In essence, the agent remains autonomous but is only allowed to act within the permitted nodes and edges due to our deterministic control flow in the background. This controlled workflow combines the advantages of autonomous agents with the security and control of classic systems.
The Model Context Protocol
Modern AI agents often need to interact with a wide range of external tools and services. But how can we ensure that these interactions are reliable, flexible, and easy to maintain? This is where the MCP comes into play.
How Does It Work?
The MCP can be seen as an abstraction layer for tools to be used by agents. MCP provides a standardized interface for exchanging information and making communication between AI and the endpoints smooth and clear. It defines how the context information (i. e. all relevant data and instructions) is structured, parameterized, and passed on. As a result, each tool knows exactly what is expected of the agent, and the agent can process the results reliably.
When using MCP, there are usually two roles: client and server. The client wants to perform a task or use a tool, or provide it to its workflows. In comparison, the server receives the request to use a tool, processes it, and returns a result.
For us developers, this means that we can integrate new tools or functions into our AI system more easily. This is because we no longer have to worry about the exact data structure, regardless of the underlying technologies.
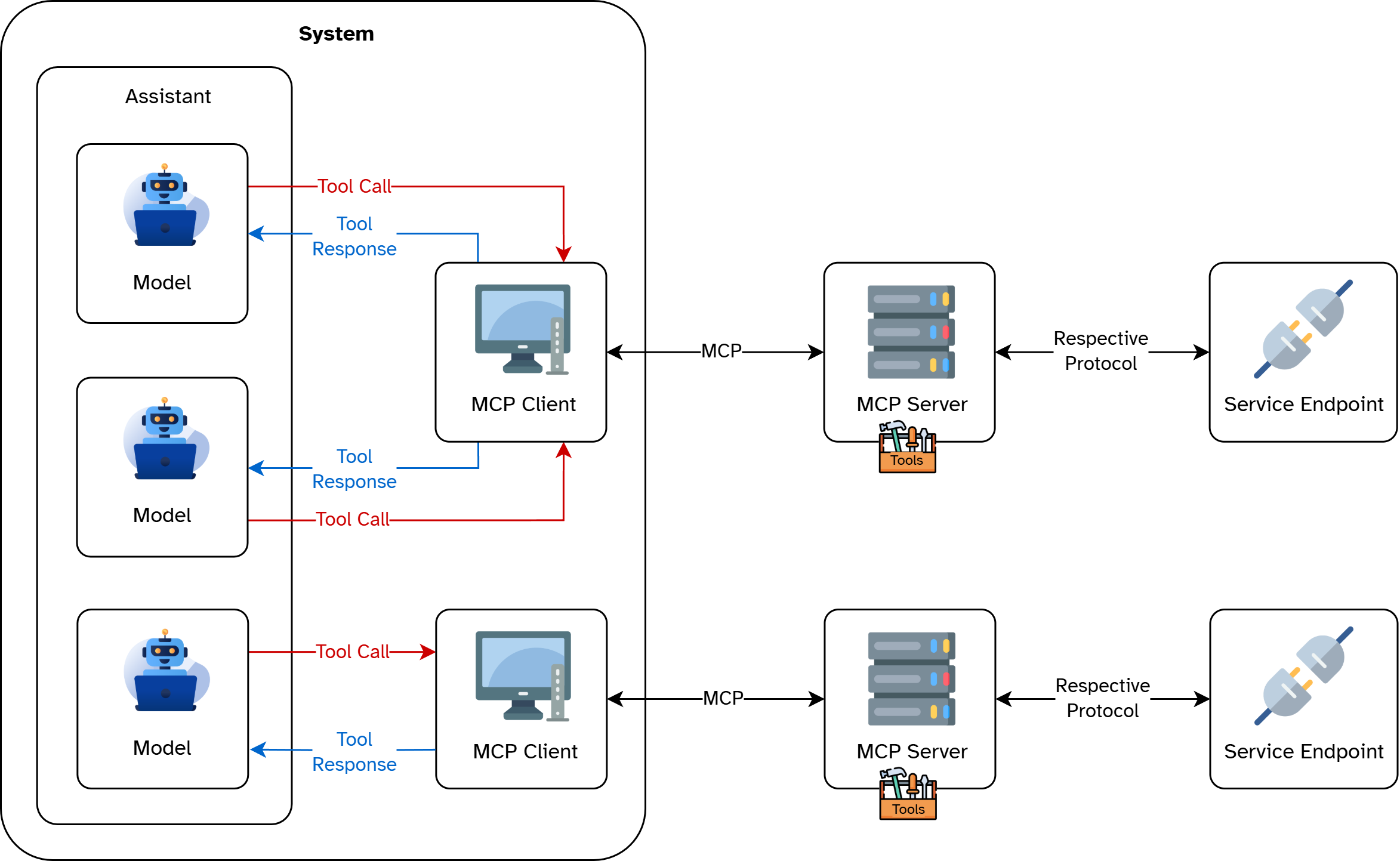
The GitLab MCP Server We Use
In our case, we want the assistant to process our requests relating to a private group with two projects in GitLab. Our assistant should not only be able to answer questions about the code and other information. It should also create GitLab resources such as issues and merge requests and make changes and extensions to code. This is exactly why we combine Agentic Workflows and MCP.
So that our assistant can use the GitLab Application Programming Interface (API) via MCP, we also need a server that offers this. We decide to use the Better GitLab MCP Server, which offers a large number of operations for interacting with GitLab.
The Assistant
The idea behind the project is to develop a coding assistant for our repositories, in which we provide an LLM internally and make it available via a chat interface. However, the assistant should not simply take over all our work. Instead, it should help us to understand the code in the various repositories by answering questions about it. The assistant should also support us in further development and debugging. Ultimately, it should provide approaches on how to solve a problem and identify bugs and errors in the code.
Apart from the technical expectations of the system, it is of course also important for us to gain experience in the development of Agentic Workflows and MCP in order to be able to share our knowledge.
Tech Stack
Our assistant is built on a carefully selected set of technologies, which enable everything from agent collaboration and workflow management to smooth user experiences and efficient integration.
- LangGraph
A python framework for building stateful, multi-agent applications with LLMs, enabling complex workflows and agent collaboration. - Chainlit
An open-source python package for quick prototyping, testing, and deploying of conversational AI apps with a user-friendly chat-interface. - Better GitLab MCP
A MCP server that provides many functionalities for retrieving and creating GitLab resources that have a unified interface for LLM communication. - Azure OpenAI — GPT-4.1
Provides access to OpenAI’s latest language models via Azure, offering advanced AI capabilities for enterprise applications.
Architecture
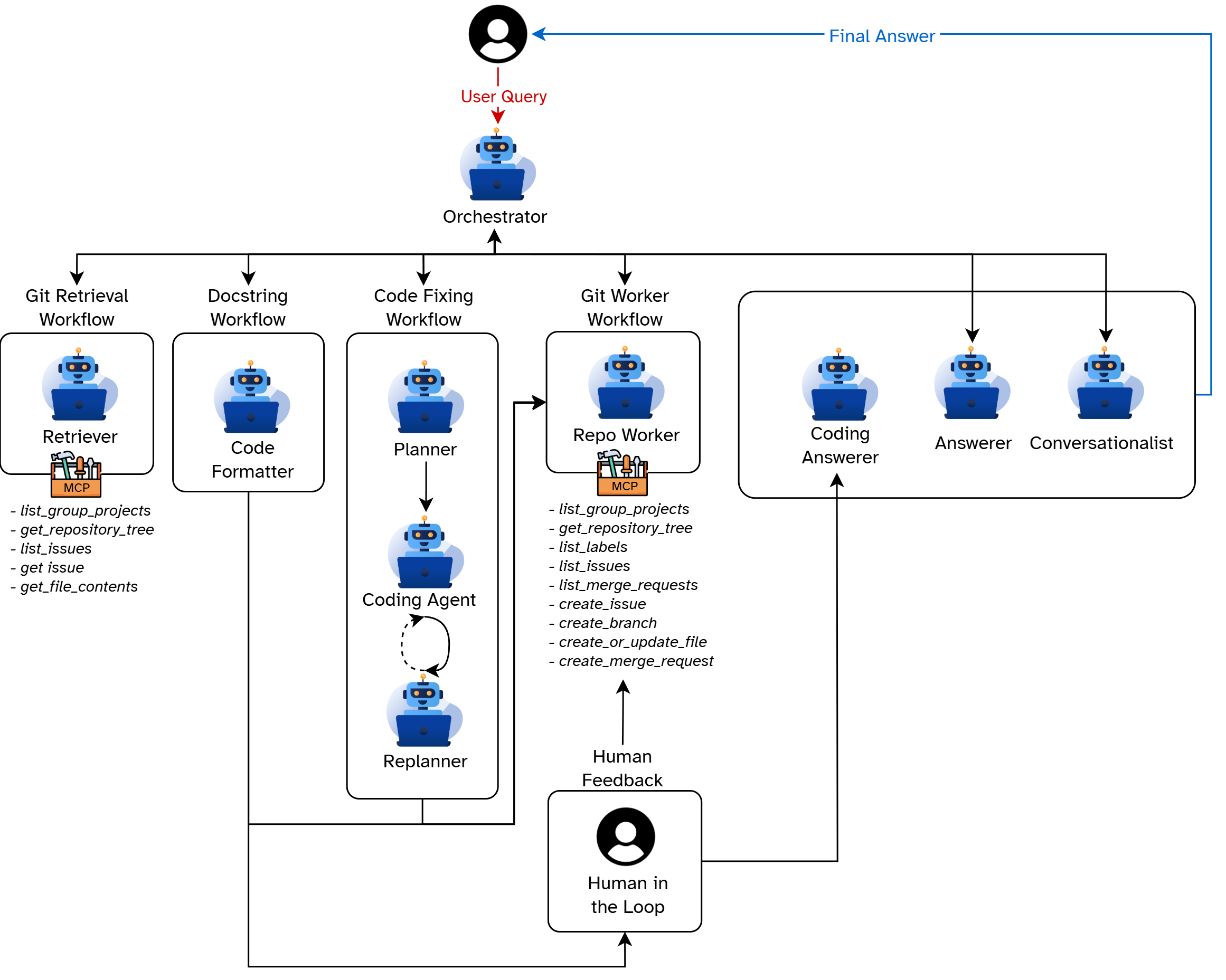
To achieve a clearer structure and greater modularity, we organize our workflow using dedicated subgraphs. We do this by relocating nodes based on their task classification. This approach enhances control and enforces separation of concerns, as each subgraph is assigned only the tools and tasks relevant to its purpose. By following this architecture and dividing tasks into distinct nodes, we simplify development. Dedicated functionalities can be designed and tested independently before integration. Thus, we reduce debugging efforts later and ensure that new features do not affect core capabilities.
- Orchestrator
Initial and central instance for deciding which subgraph to start with, to which node to route to and when processing is completed. - Git Retrieval Workflow
Responsible for retrieving information from the GitLab repository, for example in the form of code, folder structures, or text. Has a connection to the MCP server and has only access to the tools intended for it. Can get group projects, repository tree, file contents, and issues. - Docstring Workflow
Creates or improves docstrings according to the Google Python Style Guide for increased readability, maintainability, and integration. - Code Fixing Workflow
Responsible for automatically detecting, analyzing, and correcting errors or problems in the code. Consists of several individual nodes that work together.- Planner
Analyzes the given code and creates a plan of steps that must be implemented so that the code is executable and error-free. - Coding Agent
Implements the instructions in the plan and outputs the updated code after each step. - Replanner
Checks after each step whether all steps in the plan have been completed and whether the code is executable as well as error-free. If so, it terminates the execution in the subgraph; otherwise, it adds further steps to be executed to the plan.
- Planner
- Git Worker Workflow
Has the task of creating resources in the specified project while avoiding duplicates. Has a connection to the MCP server and has only access to the tools intended for it. Can get group projects, repository tree, labels, issues, merge requests; can create issues, branches, and merge requests; and can create or update files. Follows the implemented security aspects and restrictions outlined in The Importance of Implementing Security Measures. - Answerers
Specialized nodes that react and respond to different user requests depending on the context.- Coding Answerer
Summarizes the code changes and presents them to the user. If required, makes the changed files available for download or provides their corresponding created GitLab resource links. - Answerer
Answers the user’s questions about the project and/or its code, presents retrieved code, and provides links to created GitLab resources that are not associated with direct code changes. - Conversationalist
Holds a conversation with the user if there are no specific tasks or questions about the projects or the code they contain.
- Coding Answerer
- Human in the Loop
To increase interactivity and maintain greater control over the process, the assistant can ask the user callback questions, for example “Which resource should be created for the change?“
What Can Our Assistant (Not) Do?
To gain an overview of what using Agentic Workflows and MCP enables us to do, here’s a quick look at the main functionalities together with an example prompt to solve this kind of task. Each is designed to enhance our onboarding and development processes:
- Answer Questions About Project Code (Q&A)
Retrieve, understand, and summarize relevant code or documentation to answer user questions about the codebase.
→ “How does the app work?“ - Fix Code Bugs
Identify bugs in code files or snippets and suggest or apply fixes automatically.
→ “Fix this code: print(test).“ - Extend Existing Code
Generate new code, add features, or create comprehensive docstrings based on user input.
→ “Add unit tests to the function calculate_area.“ - Create GitLab Resources
Automate the creation and management of GitLab resources, with or without making code changes.
→ “Fix this code: print(test) and create a merge request for it.“
Lessons Learned When Working With Agentic Workflows and MCP
After putting Agentic Workflows and MCP to the test in combination, a few patterns and pain points became clear. Below, we’re sharing the most important takeaways from our journey, plus some concrete ideas for making the assistant even better and more reliable going forward.
Key Takeaways
Developing our assistant brought plenty of surprises – some helpful, some challenging. Here are the key lessons learned along the way, from prompt design quirks to resource demands and everything in between.
- LangGraph Helps With Development
LangGraph is ideal for the development of Agentic Workflows and MCP. Managing the models, the MCP connections, and the tools in a DAG gives you the control you need to ensure the reliability of the results. Furthermore, the subdivision into subgraphs helps to increase modularity and facilitate the extension of the system. - Workflow Behavior Is Strongly Dependent on Prompt Design
During development, we discovered that even the smallest changes in the system prompts of the LLMs can have a major impact. Especially with regard to the orchestrator, this can lead to incorrect decisions or even no decisions being made at all. It also helps a lot to divide the LLMs according to their tasks and to give them system prompts tailored to their area of responsibility – like we did with the subgraphs. - Non-Deterministic Behavior Complicates the Information Flow Control
The fact that we cannot always expect exactly the same results has an impact on various areas of development. For example, it makes testing a whole lot more difficult. This is because we have to weigh up whether we should design the tests for the system more generally so that we can intercept unpredictable results or whether we accept that tests could fail more often if one or more nodes in the DAG have a „hiccup“. Incidentally, the overall orchestration of the workflows is also made more difficult for the same reason. - Increased Resource Requirements
The nodes exchange all the information collected so far with each other (and call their available tools multiple times), thus sending a request each time. Therefore, we need considerably more resources per run. This is something we should keep in mind and which will need to be optimized in the future. As of now, we use the GPT-4.1 models for almost every node and send around 10-15 requests per task, which results in around 0.30–$0.45 for a single job.
How Can We Improve the Assistant?
In order to further improve the assistant, there are a variety of approaches ranging from usability, reliability ,and control of the process to security-related aspects. Here are a few points where we see the greatest potential.
History Management
One point we briefly touched on earlier in the Key Takeaways is that our message history is filled with all the retrieved content and the responses generated by the individual models. In the long run, however, this leads to inaccurate results. The models will take longer to process the input, and our costs will rise. To avoid these problems, there are several approaches that can be used in combination, depending on how they are used.
- Message History Management
Message history management is crucial for efficiently handling the context of longer conversations while conserving resources. Different strategies offer different advantages and disadvantages. The following approaches show how context and storage requirements can be reconciled.- Cutoff/Rolling Window
Only the lastnmessages or the lastmtokens of a conversation are saved. This method is very easy to implement and reduces the amount of data. However, important information can be lost if it lies outside the window. - Message Summaries
When older messages are summarized in the history, they are saved in compressed form. This preserves the essential context while saving memory. However, the quality of the summaries is crucial, as important information can be lost if it is compressed too much. - Indexing
Content is stored in vector databases and retrieved as required instead of keeping the entire conversation in the history. This enables efficient context management for large amounts of data but requires a more complex implementation and additional infrastructure.
- Cutoff/Rolling Window
- Separate Handling of File Contents
Similar to the Indexing strategy is the idea of managing the retrieved content of files separately. The idea here is to store the content of each file either locally or in a database and either add it to the context or withhold it from it as required. This procedure could be carried out both automatically and manually. - Pre-Fetching
In relation to the strategy of Separate Handling of File Contents, it can also make sense to load data that are frequently required when the application is started. This could include the available projects in the group, the repository tree, the files in each project, or individual high-importance files. This would prevent the nodes in the DAG from having to call certain tools themselves (possibly multiple times). In turn, this reduces costs and can also have a positive effect on the size of the history.
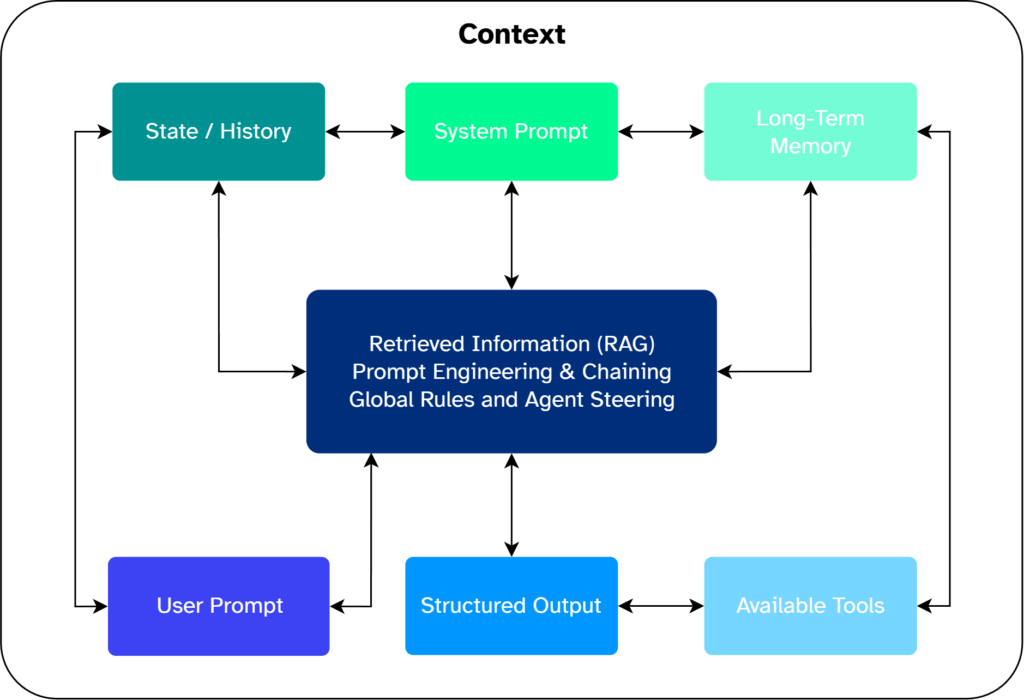
Context Engineering
The practice of context engineering is currently a hot topic. There are good reasons behind this, as we also encounter limitations concerning our agent context. We have already covered an integral part of this in the History Management. However, there are other strategies and approaches to increase the performance of the system using clever context management. In the following, we will briefly discuss the most important additional points for our case.
- Prompt Engineering and Prompt Chaining
Prompt engineering involves refining prompts with clear instructions, roles, and examples to optimize AI model responses. It requires tailoring prompts to each model’s strengths and limitations. Prompt chaining expands on this by linking prompts in stages, where the AI can even generate new prompts to further improve results. - Global Rules and Agent Steering
Global rules set consistent strategies and guidelines for every system execution, ensuring uniformity and reducing repetition by being defined once. In contrast, agent steering offers flexible, scenario-specific instructions. They can be activated as needed and tailored to particular contexts, such as applying special rules or providing extra files for specific tasks.
Increase Human Feedback / Human in the Loop
Another point is to make the system more interactive and gain more control over the execution of Agentic Workflows. Therefore, a further improvement step is to incorporate more human feedback. This approach also has the advantage that security-relevant aspects can be incorporated. For example, before any writing tool call, the user could be asked whether this action may be executed. However, this can also lead to the automation – and therefore the core idea of the system – being lost from focus. One conceivable solution would therefore be to request the execution of write operations as a batch from the user in order to avoid too many interactions.
Comprehensive Testing
Comprehensive testing is particularly important in the context of Agentic Workflows and MCP. This is because many components and models interact with each other within the DAG. By increasing test coverage, errors and unexpected behavior can be detected at an early stage. For instance, more tests help us to detect agents making wrong decisions or interfaces not working as expected. They also help to identify unstable or error-prone areas in the overall system and to analyze whether the cause lies in the code, in the design of the prompts, or in the peculiarities of the model used. In this way, it is possible to find out specifically where there is a need for optimization. Thus, this ultimately leads to a more robust and reliable orchestration of the LLMs and workflows.
The Importance of Implementing Security Measures
To make our assistant as secure as possible, we include some restrictions and special adjustments to the environment in which it operates.
A key principle is granting the system the least privilege possible. Since GitLab tokens can’t restrict individual operations, we limit the assistant’s access by assigning it the Developer role. This prevents access to critical actions like managing permissions and settings (more on this in the GitLab Permissions).
We also make several security-focused code changes. The assistant can’t access or modify its own code, as it works in a separate clone without its source. We also whitelist only approved tools, preventing the use of arbitrary MCP tools from the server. Additionally, direct commits to the main branch are blocked. All merge requests start as drafts.
Of course, these points do not offer complete protection against possible attacks, such as prompt/plan injections or memory poisoning. However, within the scope of our use, these points considerably reduce security risks. To learn more about AI risks in development, see our article Threat Modeling for AI and the Open Worldwide Application Security Project’s (OWASP) document, Agentic AI – Threats and Mitigations.
Summary
Bringing together Agentic Workflows and MCP allowed us to develop a very helpful coding assistant. It can not only understand and answer questions about our codebase but also actively supports development and resource management in GitLab. Throughout the project, we encountered both the flexibility and complexity that come with orchestrating autonomous agents. This showed especially in terms of prompt design, context handling, and the need for reliable testing. We found that balancing autonomy with control is key. Therefore, thoughtful architecture and human feedback loops can greatly enhance both reliability and security. Our experiences highlight the importance of modular design, clear responsibility separation, and continuous improvement – insights that can help guide future projects working with similar AI-driven workflows.



