
Notice:
This post is older than 5 years – the content might be outdated.
Despite the fact that machine perception systems achieve superhuman performance on different perceptual tasks, researchers have recently demonstrated that they are not infallible. Images with methodically crafted perturbations, also called adversarial examples, can deceive these systems and cause misclassification.
This is particularly problematic for face recognition systems (FRSs) because they are more and more dependent on deep learning and increasingly deployed in security-critical domains like access control, public camera surveillance (CCTV), unlock functions for mobile devices or automated security controls at airports.
FRSs are particularly vulnerable to an adversarial attack proposed by Sharif et al. [1] (here referred to as adversarial glasses attack) that is based on perturbed eyeglass frames which can be worn to mislead the system. Examples of these adversarial attacks are depicted below, where the top row shows the attackers wearing the eyeglass frames and the bottom row depicts the individuals as which the attackers are classified:

Taken from: [1]
In this article we highlight, by means of adversarial examples in general and the mentioned glasses attack in particular, the importance to make FRSs robust against these undesirable threats. Additionally, we apply, optimize and evaluate a defense method based on the adversarial example’s saliency map [2] to make a trained FRS robust to the adversarial glasses attack.
Introduction to the Dark Arts
Work by Zegedy et al. [3] has shown that neural networks for image classification tasks can be deceived with artificially crafted prediction inputs, known as adversarial examples. Since this discovery, numerous approaches for generating adversarial examples have been proposed, aiming to lead machine perception into some sort of misclassification. Most commonly, this goal is achieved by crafting subtle perturbations that are added to the image in order shift the classification output towards the intentions of the attacker.

Taken from: [4]
As visualized above, the adversarial perturbations are oftentimes imperceptibly small so that adversarial examples remain indistinguishable from the original images for humans. Consequently, without perceptible differences between these two, a human would label the adversarial example with the original class whereas the classifying neural network is likely to predict the class that was set by the attacker generating the example.
The adversarial glasses attack [1] follows a different approach. Its adversarial perturbations are visible adversarial perturbation bound to eyeglass frames, allowing for the generation of adversarial perturbed glasses that can be worn by the attacker in the physical world. This causes an FRS to classify them as a different person while staying relatively inconspicuous. The adversarial glasses attack is conducted in 3 Steps:
- First, the glasses are rendered in any color on the attacker’s face. Similar to the creators of the attack, we initialize the frame of the glasses in yellow.
- Once this is done, the adversarial perturbations are generated within the area of the eyeglass frames. This is done by iteratively solving an optimization problem with gradient descent, so that the classification result is shifted gradually towards the target class. In each iteration, the resulting gradients are added with small increments as color values to the pixels of the glasses, which gradually creates the multicolored patterns. The generation process is terminated as soon as a threshold value for the target class confidence is met.
- Finally, the attacker can print out the generated adversarial glasses in order to put them on and be recognized as different person.
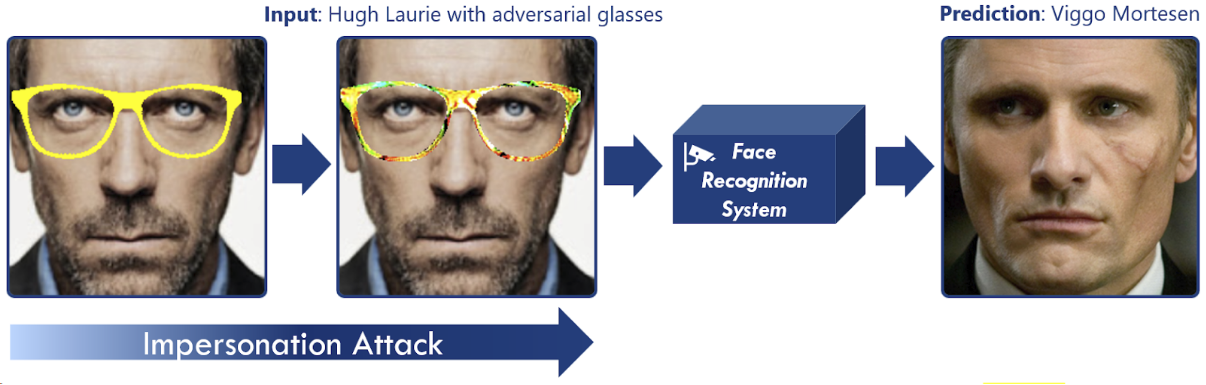
The 4th step is consequently the physical realization of the adversarial glasses attack. Evaluating physically realized attacks requires great carefulness and accuracy throughout the process of printing out and recapturing the adversarial glasses. Otherwise the adversarial glasses loose expressiveness and would not survive this process. For instance, we were not able to provide light conditions for which the captured images of the printed eyeglasses do not have distorted color values compared to the digitally generated adversarial examples, leading to a high rate of failure for these attacks. For this reason, we evaluate defenses against the adversarial glasses attack solely in the digital domain.
Defense Against the Dark Arts
Making machine perception systems robust against adversarial examples is a widely discussed task among researchers and has received just as much attention in the recent past as the adversarial attacks themselves. It is therefore no coincidence that numerous methods have already been proposed to achieve this goal—with more or less success. In general, the choice of the right defense strategy depends on the environment in which the attacker is expected to place his adversarial examples. Regarding FRSs as they typically operate in the physical world, the attacker does not have direct control over the adversarial example as it is fed to the classifier model. Rather these systems fetch their input data from cameras or other sensors. In such a scenario the attacker is able to influence the classification result solely by changing the physical appearance of the predicted adversarial example. This can be done especially well by visible adversarial perturbations just like the adversarial glasses attack. This is why we wish to have a defense that makes FRS not only robust to adversarial eyeglasses but also to other visible adversarial perturbations in the form of accessories that can be potentially worn as well.
With that in mind, we choose a method that utilizes the saliency map of the adversarial example (subsequently referred to as Saliency Mask Method) [2]. A saliency map depicts the influence of the image’s spatial areas on the classification result. An example is shown below, with darker regions of the saliency map representing areas with a higher impact on the classification result:

As visible adversarial perturbations usually induce a dense cluster of high neuron activity, the saliency map can be transformed into a mask that covers the unnaturally dense regions and uses it as stencil to remove them. Since detecting these regions is theoretically possible for arbitrary shapes and at any position, the saliency mask methods potentially generalizes to other imaginable adversarial accessories as well. The crucial challenge is how to detect the regions with visible adversarial perturbations. To tackle this problem, the saliency mask method generates a saliency mask for each adversarial example. This procedure is depicted and described below:

- Generate the saliency map with the Guided Backpropagation algorithm [5]. For a given classifier model, the algorithm considers the forward pass which is the model’s information flow from an input image to an output vector and the backward pass denoting the backpropagation of the output layer’s gradients with respect to the input image. For each ReLU activation unit of the classifier model it is checked if the the forward pass or the backward pass through that unit is negative. If that is the case, the influence signal is set to zero. In this way only the positive activations—which are the ones that influence the given classification output—are taken into account while backpropagating the influence signal for generating the saliency map.
- A first version of the saliency mask is created by masking values of the generated saliency map that exceed a fixed pixel threshold μ. This intends to mask only parts of the image which have a particularly high impact on the prediction outcome (i.e. high entries in the saliency map).
- Dilation followed by erosion applied for n iterations to fill small holes in the masked region. Dilation enlarges the masked contours by a small structuring element whereas erosion enlarges the non-masked contour (i.e. it erodes the masked contours). When used together, erosion and dilation close small “holes“ in the masked regions so that contiguous contours are formed. The Number of iterations n determines the intensity of this procedure.
- All contiguous contour areas are identified and zeroed out if their size which doesn’t reach a certain contour size threshold φ. It can be seen that in step 2 that many pixels are masked which are part of the actual image as well and don’t belong to the adversarial glasses. The contour size threshold helps to sort these contours out because the detected adversarial regions are usually bigger than contours that cover clean regions, thanks to step 3.
- Finally, the mask is applied to the adversarial examples to remove the adversarial perturbations.
Let’s move on to the action
Preparations
To evaluate the adversarial glasses attack a dataset of labeled faces is needed. To that end, the PubFig development set is consulted which contains various images of 60 different celebrities that are cropped to the area of the faces. Out of these, we selected 30 individuals to form a small dataset for training and evaluation.
For the choice of the FRS architecture for the most part we kept to the paper that introduced the adversarial glasses. It is basically a VGG16 convolutional neural network, as shown below:
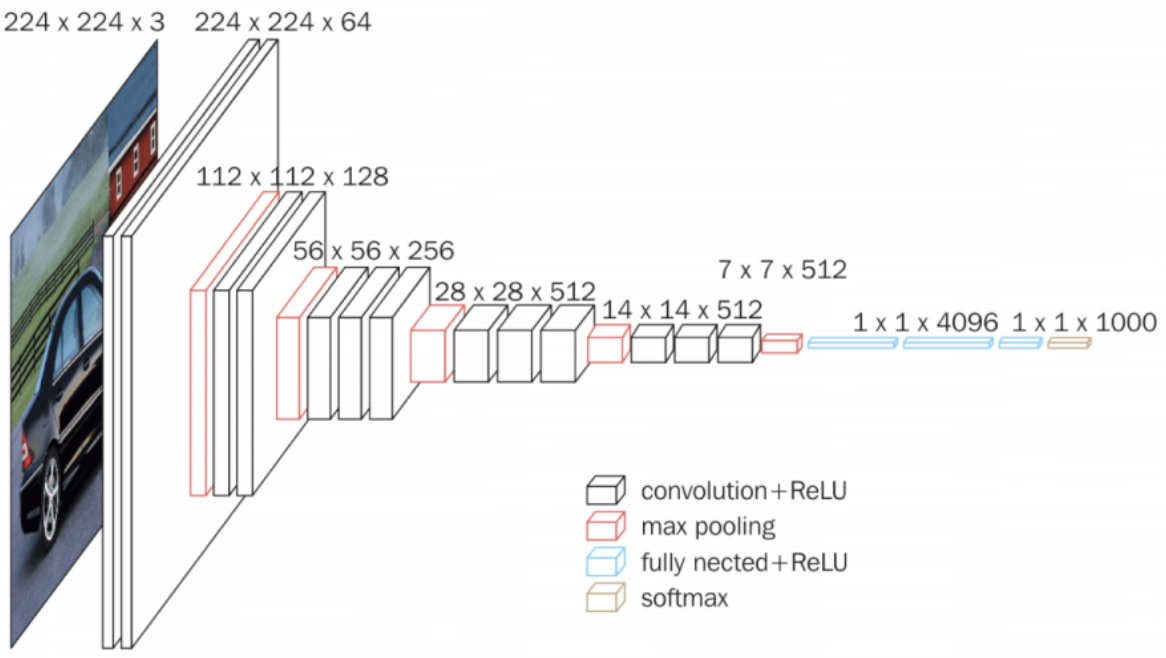
Taken from: https://neurohive.io/en/popular-networks/vgg16/
As our dataset is relatively small (~2300 images) we use transfer learning to adequately train the neural network. For this purpose, the 13 convolutional layers are copied from a VGG16 net that had been pre-trained on a similar task. In particular, the layers were trained on the vggface dataset and frozen during our training so that the weights stayed unchanged. We only trained the subsequent fully connected layers on our new task. Consequently, the dependency on large amounts of data for training the neural network was significantly reduced. Finally, we trained the model for 45 epochs with a 80/20 train-validation-split which resulted in a training accuracy of 98,9% and a validation accuracy of 98,1%.
Besides training the FRS, an important preparation for the final evaluation is to analyze how the saliency mask method can be optimized. It reveals three interesting parameters that can be adjusted to tune the defensive performance:
- Pixel threshold μ
- number of iterations n for dilation + erosion
- Contour size threshold φ
To find optimal values, we perform a grid-search on appropriate value ranges for all three parameters. This way we found that the hyper-parameter values proposed by the original paper of the saliency mask method were not optimal for the purpose of this work. The actual intention of the grid search is to find the best setup for maximizing a metric that grades the defensive performance. For this purpose, we define a goodness score which is a metric that measures the level of achieving the desired defensive behaviour. We define it to incentivize the following objectives:
- Retain high accuracy on clean examples
- Achieve high accuracy on adversarial images
- Achieve a low adversarial success rate
To get a balanced ratio between these objectives, we define the goodness score as:
\(goodness score= 1/3 * ( AC(clean, r) + AC(adv, r) + (1-AC(adv, t))) \)
\(AC(X, Y) \) represents the average confidence at which the FRS predicts a set of images \(X (clean / adversarial) \) as a set of classes \(Y (r = real / t = target)\). Due to the definition, the goodness score ranges between 0 and 1 where low values indicate poor and and high values indicate a good defensive performance.
Finally, the goodness score is monitored for all possible hyper-parameter combinations and the combination that triggers the highest goodness score is applied to perform an evaluation of the saliency mask method on the adversarial glasses attack.
Results
The table below shows the hyper-parameter combinations that produced the highest values for each defense objectives and the goodness score after the saliency mask method is applied. The parameter combination μ=0.98, n=8 and phi=80$ resulted in the highest measured score of 0.7768.

Let us now take a closer look on the results that can be achieved by this parameter combination. Firstly, it is interesting to see what adversarial examples that were processed by the saliency mask method look like. For the found parameters, the plot below shows samples for which the defense method worked out as intended:

It is apparent that only a small part of the adversarial glasses has been actually masked. We will discuss this in the following section in more detail. Beforehand, let’s examine important performance measures for the Saliency Mask Method with the given parameter values:
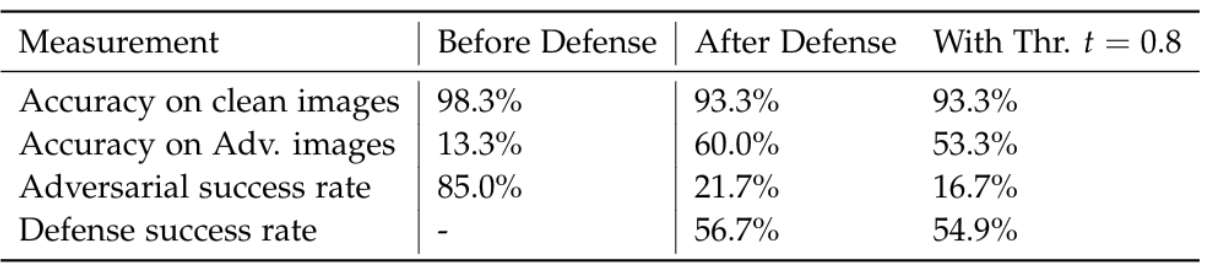
It shows that its usage effects a significant drop of the adversarial success rate from 85.0% to 21.7% while increasing the percentage of correctly classified adversarial images from 13.3% to 60.0% and maintaining a relatively high accuracy on clean images of 93.3% (before 98.2%). When accepting classification only if the confidence is above a threshold arbitrarily set to 0.8, the adversarial success rate can be further reduced to 16.6% with unchanged accuracy on clean images, though this comes with a decrease of 6.7% in the accuracy on adversarial examples as well. Adjusting the threshold to potentially achieve even better results is surely worth consideration but this step is out of the scope of this article. Eventually, the defense success rate which is the percentage of adversarial examples predicted as target class before and as real class after the defense is applied, is 56.7% without and 54.9% with a threshold applied.
Conclusion
In the context of adversarial examples, the reliability of machine perception is nothing that should be taken for granted. Carefully crafted attacks like the adversarial glasses attack are a real threat to the safety of FRSa as they allow for deceiving artificial neural networks in a practical and realizable manner.
Defending adversarial examples is a broadly discussed task which has no trivial and universal solution, especially if the attacker knows which strategy is used to defend against his adversarial examples. Whereas many defense approaches have been proposed to defend against adversarial examples in general, so far there has been little work in the defense of adversarial examples designed to fool FRSs, just like the adversarial glasses attack. To shed light on the dark, we applied the saliency mask method and demonstrated that it is suitable for making a FRS robust against the adversarial glasses attack. Its presence caused a significantly increased accuracy on adversarial examples while maintaining a relatively high accuracy on natural images.
The fact that the saliency mask method works on the basis of saliency maps makes it seem to be effective against all imaginable kinds of adversarial accessories. However, the adversarial glasses attack proves that optimizing the method’s parameters is crucial for achieving reasonable results. The optimal parameters tend to be dependent on the adversarial attack that is to be defended which is eventually a slight drawback for the generalizability of the saliency mask method.
References
- [1] M. Sharif, S. Bhagavatula, L. Bauer, and M. K. Reiter, “Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition“, 2016
- [2] J. Hayes, “On Visible Adversarial Perturbations & Digital Watermarking“, 2018
- [3] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks“, 2013
- [4] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and Harnessing Adversarial Examples“, 2014
- [5] J. T. Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller, “Striving for Simplicity: The All Convolutional Net“, 2014
- [6] D. Karmon, D. Zoran, and Y. Goldberg, “LaVAN: Localized and Visible Adversarial Noise“, 2018


