
Notice:
This post is older than 5 years – the content might be outdated.
In previous blog articles we talked about the basic Redis features and learned how to persist, backup and restore your dataset in case of a disaster scenario. Today we want to introduce you to a more complex setup. In fact, you can teach your Redis instances to be highly available for your clients.
At this point the Sentinel jumps in. So what is this Sentinel stuff? The Sentinel process is a Redis Instance which was started with the –sentinel Option (or redis-sentinel binary). It needs a configuration file that tells the Sentinel which Redis master it should monitor.
In short, these are the benefits of using Sentinel:
- Monitoring: Sentinel constantly checks if the Redis master and its slave instances are working.
- Notifications: It can notify the system administrators or other tools via an API if something happens to your Redis instances.
- Automatic Failover: When Sentinel detects a failure of the master node it will start a failover where a slave is promoted to master. The additional slaves will be reconfigured automatically to use the new master. The application/clients that are using the Redis setup will be informed about the new address to use for the connection.
- Configuration provider: Sentinel can be used for service discovery. That means clients can connect to the Sentinel in order to ask for the current address of your Redis master. After a failover Sentinel will provide the new address.
Configuration and example setup with three nodes
The Sentinel processes are a part of a distributed system. That means your Sentinel processes are working together. For a high availability setup we suggest using more than one Sentinel, as Sentinel itself should not be a single point of failure. It also improves the proper failure detection via quorum.
Before you deploy Sentinel, consider the following facts. More in-depth information on the most important points can be found below:
- At least Three Sentinel instances are needed for a robust deployment.
- Separate your Sentinel instances with different VMs or servers.
- Due to the asynchronous replication of Redis the distributed setup does not guarantee that acknowledged writes are retained during failures.
- Your client-library needs to support Sentinel.
- Test your high availability setup from time to time in your test environment and even in production systems.
- Sentinel, Docker or other NAT/Port Mapping technologies should only be mixed with care.
A three node setup is a good start, so run your Redis Master and two Slaves before setting up the Sentinel processes. On each of your Redis Hosts you create the same Sentinel config (/etc/redis-sentinel.conf, depending on your Linux distribution), like so:
|
1 2 3 4 5 6 7 8 9 |
sentinel monitor myHAsetup 192.168.1.29 6379 2 sentinel down-after-milliseconds myHAsetup 6001 sentinel failover-timeout myHAsetup 60000 sentinel parallel-syncs myHAsetup 1 bind ip-of-interface |
Let’s dig deeper and see what these options do:
- This line tells Sentinel which master to monitor (myHAsetup). The Sentinel will find the host at 192.168.1.3:6379. The quorum for this setup is 2. The quorum is only used to detect failures: This number of Sentinels must agree about the fact that the master is not reachable. When a failure is detected, one Sentinel is elected as the leader who authorizes the failover. This happens when the majority of Sentinel processes vote for the leader.
- The time in milliseconds an instance is allowed be unreachable for a Sentinel (not answering to PINGs or replies with an error). After this time, the master is considered to be down.
- The timeout in milliseconds that Sentinel will wait after a failover before initiating a new failover.
- The number of slaves that can sync with the new master at the same time after a failover. The lower the number the longer the failover will need to complete. Using the slaves to serve old data to clients, you maybe don’t want to re-synchronize all slaves with the new master at the same time as there is a very short timeframe in which the slave stops while loading the bulk data from the master. In this case set it to 1.If this does not matter set it to the maximum of slaves that might be connected to the master.
- Listen IP, limited to one interface.
After you set up the Sentinel configuration for your instances, start it via init script, systemd unit or simply via its binary (redis-server /path/to/sentinel.conf –sentinel). The Sentinel processes will discover the master, slaves and other connected sentinels and the system is complete. Let’s see now what the setup looks like and what happens during a failover.
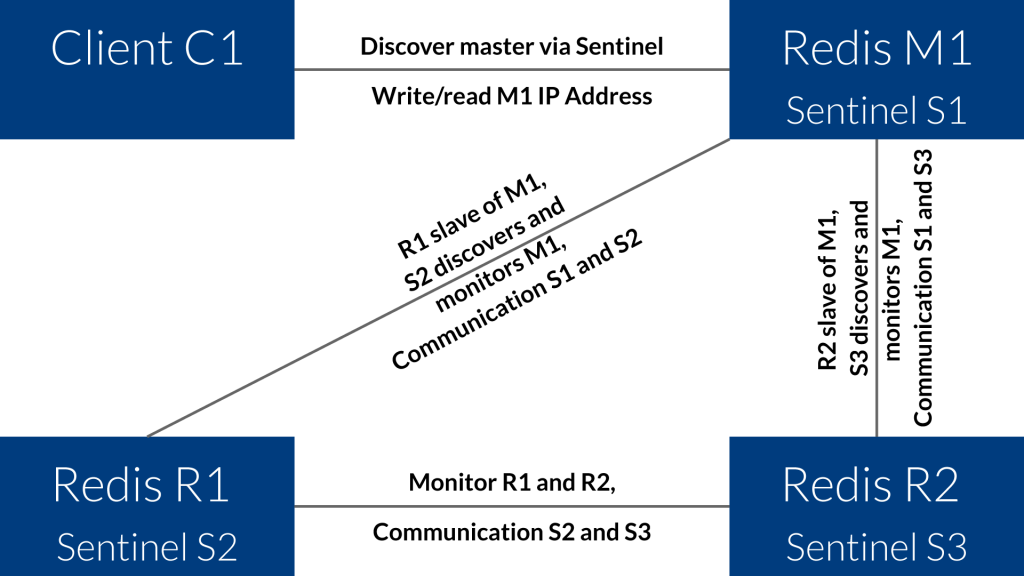
We have three Redis instances and three Sentinel instances:
M1 = Master
R1 = Replica 1 / Slave 1
R2 = Replica 2 / Slave 2
S1 = Sentinel 1
S2 = Sentinel 2
S3 = Sentinel 3
Let’s check the status of the Sentinel: Via the option -p 26379 you connect directly to the Sentinel API.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
redis-cli -p 26379 -h 192.168.1.29 info sentinel # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=myHAsetup,status=ok,address=192.168.1.29:6379,slaves=2,sentinels=3 |
As you see the Sentinels are monitoring one master “myHAsetup“, their status is OK and you can see how many slaves and other Sentinels are discovered.
|
1 2 3 4 5 |
redis-cli -p 26379 -h 192.168.1.29 sentinel get-master-addr-by-name myHAsetup "192.168.1.29" "6379" |
So far so good, everything looks fine. Now let’s see what happens when the master is unresponsive: We can simulate an outage by issuing the following command.
|
1 |
redis-cli -p 6379 -h 192.168.1.29 DEBUG sleep 30 |
This produces the following log file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
1. 3643:X 29 Jul 13:45:08.957 # +sdown master myHAsetup 192.168.1.29 6379 2. 3643:X 29 Jul 13:45:09.328 # +new-epoch 1 3. 3643:X 29 Jul 13:45:09.329 # +vote-for-leader 040e143e5bb2608cc1df4bb21c9da6dc728330ab 1 4. 3643:X 29 Jul 13:45:10.051 # +odown master myHAsetup 192.168.1.29 6379 #quorum 3/2 5. 3643:X 29 Jul 13:45:10.051 # Next failover delay: I will not start a failover before Fri Jul 29 13:46:10 2016 6. 3643:X 29 Jul 13:45:10.486 # +config-update-from sentinel c367ad28d070b7447c3bd9d0a6a0ab046bbc30fc 192.168.1.30 26379 @ myHAsetup 192.168.1.29 6379 7. 3643:X 29 Jul 13:45:10.486 # +switch-master myHAsetup 192.168.1.29 6379 192.168.1.31 6379 8. 3643:X 29 Jul 13:45:10.486 * +slave slave 192.168.1.30:6379 192.168.1.30 6379 @ myHAsetup 192.168.1.31 6379 9. 3643:X 29 Jul 13:45:10.486 * +slave slave 192.168.1.29:6379 192.168.1.29 6379 @ myHAsetup 192.168.1.31 6379 10. 3643:X 29 Jul 13:45:16.499 # +sdown slave 192.168.1.29:6379 192.168.1.29 6379 @ myHAsetup 192.168.1.31 6379 11. 3643:X 29 Jul 13:45:32.435 # -sdown slave 192.168.1.29:6379 192.168.1.29 6379 @ myHAsetup 192.168.1.31 6379 12. 3643:X 29 Jul 13:45:42.442 * +convert-to-slave slave 192.168.1.29:6379 192.168.1.29 6379 @ myHAsetup 192.168.1.31 6379 |
Here a short summary of what happens
- Failure is detected
- Config-Version Epoch is increased by +1
- Leader is elected
- Quorum check. 3 Sentinels see the master down
- Delay for the next possible failover, after the current one
- – 10. Failover to the new master, reconfiguration of the slave nodes (old master 192.168.1.29 is already marked as slave and down at the moment)
- Old master comes back to the setup (after hanging in DEBUG for 30 seconds)
- Old master is converted to slave and synchronizes to the new master.
Another check with the Sentinel API confirms the new master:
|
1 2 3 4 5 |
redis-cli -p 26379 -h 192.168.1.29 sentinel get-master-addr-by-name myHAsetup "192.168.1.31" "6379" |
At the end downtime sums up to around 7-8 seconds (6 to detect the failure + 1-2 seconds to fulfill the failover). With a stable network setup without flapping you might be able to reduce the failure detection from 6 seconds to 3 seconds, thus minimizing the downtime, during which no writes are accepted.
Maintainance
So how do you maintain such a setup? In general the procedure is similar to other high availability setups: Before you start, take a backup of your keyspace with an RDB snapshot and copy it to save place, e.g. by updating the redis.conf and increasing the ‚maxmemory‘ parameter or modifying the save parameter for the RDB snapshot engine.
- stop Redis at one slave node
- update the config file
- start Redis
- wait until the node is synchronized properly
- repeat for the second slave
- repeat for the master node (causing a failover)
- change complete
Another example, where you want to update the redis-package:
- check the change-log from the new Redis version, if there was no harmful change you can go on
- backup your keyspace, best would be a RDB snapshot
- stop Redis and Sentinel
- copy both config files to a save place on the server
- update the Redis package
- copy both configs from save place to the config-dir (/etc/)
- start Sentinel
- check whether the updated Sentinel starts and is considered active by the other Sentinels
- if not, check the logfile for the cause of the issue
- if yes, start Redis and check the startup and logfile if everything looks fine
- repeat for the other slave, and then for the master.
- update complete
After these two examples we inspect the Sentinel with its API:
|
1 2 3 |
redis-cli -p 26379 -h 192.168.1.29 PING PONG |
This is very simple – but shows that the Sentinel works properly. To bring this article to a close, let’s take a look at some advanced commands. They all follow roughly the same pattern:
|
1 |
redis-cli -p 26379 -h 192.168.1.29 sentinel |
| redis-cli info | Complete info about the redis-instance |
|---|---|
| redis-cli info server | Server Information, cersions, configs, binary |
| redis-cli info clients | Connected clients |
| redis-cli info memory | Statistics about memory usage and limits |
| redis-cli info persistence | Info about RDB and AOF |
| redis-cli info stats | Connection, network, keyspace statistics |
| redis-cli info replication | Replication settings and status |
| redis-cli info cpu | CPU utilization |
| redis-cli info cluster | Cluster settings and status |
| redis-cli info keyspace | Display dbs and number of keys |
Conclusion
This was a short overview of the concept of Sentinel, the configuration and maintenance of the system. For more, have a look at the sentinel description page. After all there is lot more to discover.
Read on
Our upcoming articles will cover the creation of a Redis cluster and the advanced usage of the Redis CLI and monitoring capabilities. Until then have a look at our website to find out about the services we offer in data center automation, write an email to info@inovex.de for more information or call +49 721 619 021-0.
Join us!
Looking for a job where you can work with cutting edge technology on a daily basis? We’re currently hiring Linux Systems Engineers (m/w/d) in Karlsruhe, Pforzheim, Munich, Cologne and Hamburg!



2 Kommentare