
Notice:
This post is older than 5 years – the content might be outdated.
Welcome to the Jungle! Not a day goes by without the introduction of a new tool or framework that you should use in your container and orchestration setup. Well, you’ve probably settled for Kubernetes, but have you thought about alternative container runtimes to use within? My goal is to give a comprehensive, mid-level sightseeing flight over the jungle that keeps growing every day. Low enough for you to probably spot some details on the ground and learn some technicalities, but high enough not to crash and burn next to, say, a big Docker palm tree. I’m really liking this analogy.
This post is divided into three parts, the first of which you can skip if you’re familiar with OCI, CRI, CNI and already know about the complexity the term “container runtime“ has. The second part describes classic container runtimes, the third takes a look at VM-like and otherwise “special“ runtimes. Finally, in the conclusion, I’ll summarize my findings, so head there if you’re looking for an executive summary.
Part One: Foundations
To better navigate the jungle that is the current container landscape, we’ll have a brief look at standardization efforts that have been made in recent years.
The Open Container Initiative
Formed in 2015 by Docker, CoreOS and others, the Open Container Initiative’s (OCI) mission is to create open industry standards around container formats and runtimes. If a container runtime is OCI-compliant, it means that it implements specifications the OCI defines: Namely the image-spec and/or the runtime-spec. The former defines an interoperable format to build, transport and prepare a container image to run; the latter describes the lifecycle of a running container and how a tool executing such a container must behave and interact with it.
Additionally, the OCI develops reference implementations for their specifications. I’ll talk about those later. You’ll find more information about the initiative itself on the OCI website.
The Container Runtime Interface
The Container Runtime Interface (CRI) was introduced in the Kubernetes 1.5 release. Prior to this release, the kubelet (the managing instance of every Kubernetes node) and the runtime responsible for running containers were quite intertwined. This lead to high implementation efforts and wasn’t desirable, since the wishlist of container runtimes for Kubernetes to support was (and still is) growing.
With the CRI, the Kubernetes developers created a well-defined interface to develop container runtimes against. If a certain container runtime implements the CRI, it is able to be used with Kubernetes. If you’re interested in the (surprisingly concise) API itself, check out the CRI codebase.
The Container Network Interface
Our last three-letter acronym in this foundation part: Container Network Interface (CNI). It belongs to the CNCF (Cloud Native Computing Foundation) and defines how connectivity among containers as well as between the container and its host can be achieved. The CNI is not concerned with the properties or architecture of the container itself, which makes it narrow-focused and simple to implement. This statement is supported by the list of organizations and enterprises that committed themselves to the CNI for their projects: Kubernetes, OpenShift, Cloud Foundry, Amazon ECS, Calico and Weave, to name a few. Find the CNI and a more extensive list on GitHub.
Disambiguating The Term “Container Runtime“
By now, I have used the term “container runtime“ a lot. Bear with me, it’s going to appear quite a bit throughout. For this post, I want to clarify what I mean by it, because it is an overloaded term. Ian Lewis dedicated a four-part blog series to this topic, I recommend you check it out. The gist of the series: On the one hand, there are low-level container runtimes that literally run a container. These might implement the OCI runtime spec. On the other hand, there are high-level container runtimes that bundle a lot of additional functionality. Think of building and unpacking images, saving and sharing them, and providing a CLI for interaction.
These definitions of high-level and low-level container runtimes are not standardized, but they help when categorizing different projects. As we’ll see, high-level runtimes often incorporate low-level runtimes that are otherwise standalone projects.
To summarize the foundation part: If tomorrow you get the urge to add your own container project to the ever-growing jungle, you should make it OCI-, CRI- and CNI-compliant. These are the dominating standards for containerization and shape the development of both cloud and local applications of containers at the time.
Part Two: Classic Container Runtimes
Enough with the acronyms. Let’s see how they apply to the real world and what runtimes are out there. I’ll start with classic container runtimes, in the sense that all of these use the technology commonly referred to as containerization: Using a common host, and separating containers with Linux tools like namespaces and cgroups.
Docker
Let’s start with Docker, as it’s the container runtime most people know. In fact, I think Docker profited somewhat from the Kleenex effect, where a brand name is genericized—in this case, some people tend to think that Docker equals container. This is not the case, it was just one of the earlier famous solutions for containerization. When it initially came out in 2013, Docker was a monolithic software that had all the qualities of a high-level container runtime.
With standardization efforts being pushed by individuals as well as companies like Docker Inc. itself, the Docker ecosystem changed. Certain functionalities were decoupled and outsourced in standalone projects: containerd became the new high-level daemon for image management, runc emerged as the new low-level container runtime. Today, whenever you use Docker, you actually use a stack consisting of a docker daemon making calls to containerd, which in turn calls runc. Some people have argued that it is not necessary to use Docker altogether; as it just adds an extra step and therefore instability to your container management. In the case of Kubernetes, the difference is shown in figure 1.

Figure 1: Docker vs. containerd in a Kubernetes context. The dockershim and cri-containerd implementations make the respective APIs CRI-compliant by translating calls back and forth.
Well, if we get rid of Docker, how do containerd and runc hold up on their own?
containerd
containerd is a standalone high-level container runtime, able to push and pull images, manage storage and define network capabilities. It is also capable of managing the lifecycle of running containers by passing corresponding commands to a low-level container runtime like runc.
Depending on your use case, you can talk to containerd directly in a local setup by using ctr, a barebone CLI for communicating with containerd. In Kubernetes, we’ve already seen how containerd can replace a Docker-based setup by using the cri-containerd implementation. Furthermore, containerd fulfills the OCI specification both for images and the runtime (again, in the form of a low-level runtime).
With the Kubernetes Runtime Class, it is possible to use containerd as a central high-level container runtime in your cluster, but to allow for multiple low-level container runtimes to be used depending on your requirements (performance and speed vs security and separation). This sort of plugin-based scenario, depicted in figure 2, cannot be achieved with the dockershim we saw earlier.
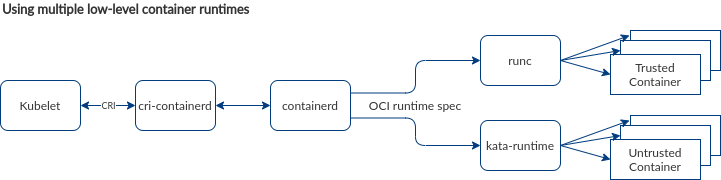
Figure 2: containerd allows for the usage of multiple low-level container runtimes, which can be used in Kubernetes interchangeably based on the requirements for a specific application. In this case, Kata is used to run untrusted containers. We’ll talk about Kata in detail in part three.
runc
I mentioned earlier that the OCI also provides some reference implementations for their specs. runc is one of them and aims for strict convergence to the OCI runtime-spec. Initially, runc emerged from the Docker project (its previous name was libcontainer) and was donated to the OCI, which has been in charge of it since.
With its scope being solely focused on managing a running container, runc can be considered a low-level container runtime. It uses the aforementioned namespaces and cgroups to provide isolation. Looking at the runc GitHub repository, you’ll see it’s implemented as a CLI you can use for spawning and running containers.
If you want to play around with runc locally, you have to obtain an OCI container image—this can be achieved with Dockers export command. After exporting the image and creating a basic specification for the container, you can use runc directly instead of Docker to run the image.
Rocket (rkt)
Apart from Docker, rkt was the only container runtime that was integrated within the kubelet directly before CRI was introduced. It was managed by CoreOS, which has been acquired by RedHat. rkt aspired to be a high-level container runtime, while also providing low-level capabilities. As of march 2020, rkt is declared dead. I’ll keep it in here for completeness‘ sake and historic reasons. And, as the EOL announcement states, it is free software that you could continue to use and develop yourself if you wanted.
rkt had some interesting features; it did not rely on a daemon but rather worked with the “rkt run“ command directly, which made it easier to use rkt in combination with systemd. Also, the Kubernetes concept of a pod was directly adopted into rkt.
Linux Containers (lxc)
Linux Containers (lxc) exist since 2008 and were initially a technology Docker was based on. The concept behind lxc is a Virtual Environment (VE), which is different from a Virtual Machine (VM) in that it doesn’t emulate hardware. VEs run directly on the host and therefore have a performance advantage over traditional VMs.
lxc can be used in combination with lxd, a container manager daemon that wraps around lxc with a Rest API. The focus of Linux Containers are base images (e. g. Ubuntu) rather than application-tailored images like we’re used from Docker and Co. Even though lxc and lxd are used successfully in production, you hardly find them inside a Kubernetes setup or as a solution for local container-based development. They also don’t implement any of the standards I introduced in part one.
Singularity
Singularity was not on the original list for this post, but a co-worker recommended to add it as it is quite famous for its use in academics and research. It focuses on high performance computing scenarios like scientific studies conducted with lots of data, aiming to make the results easily reproducible. For the most part, the project is written in Go.
Considering the standards I’m using here for evaluation, this project scores. Even though it defines its own image format Singularity Image Format (SIF), it also supports both the image and runtime spec of the OCI, which means you can port e. g. Docker images without too much hassle. There is a Singularity CRI too, that you can use in your Kubernetes cluster to run HPC workloads with Singularity, while using any other runtime for your standard workloads. You can dive into the project’s extensive documentation if you want to learn more.
Need for stronger separation
A lot of real-world setups depend on multi-tenancy, which means a lot of potentially untrusted applications run in containers side by side in a Kubernetes cluster; with the requirement that applications are still safe and functional, even if one application is compromised. You might have heard of container escape vulnerabilities like CVE 2019-5736 that give an attacker root access to the host. This can have catastrophic consequences, also for other applications run by different tenants, which is why we’ll now look at alternatives that use VM-like separation.
Part Three: VM-like Container Runtimes
To address the challenges of containerization, projects like Kata Containers, Nabla and gVisor approach the encapsulation of applications differently: By using methods usually associated with Virtual Machines (VM). Short recap: With VMs, the separation of concerns happens on a lower level than containers achieve it through cgroups and namespaces. Instead, an entire hardware stack is virtualized, so every application essentially uses its own operating system. Everything is managed by a hypervisor on the host running the VMs. Let’s see how the 60-year-old concept got integrated into the realm of container technology.
A Word About Unikernels
Wait a minute, you might say, there are reasons why we moved from VMs to containers in the first place! Of course you’re right: VMs are fully functional computers, which means a lot of unnecessary system libraries take up space, slow down boot time and increase the attack surface. A single-purpose application might only need a fraction of what is usually included in a general-purpose OS. Unikernels have been addressing this since the 1990s. The concept is straightforward: Take just the what you need out of both the user and the kernel space, and bake it into a highly customized OS supporting only the needs of your application, as shown in figure 3.

Figure 3: Unikernels only contain the parts of the OS they need and get deployed on top of a hypervisor/VMM.
The result is a small, fast-booting image with a smaller attack surface (e. g. build your image without a shell to avoid this vector). However, Unikernels aren’t without downsides: Like containers, every change to the application necessitates a rebuild of the unikernel. Monitoring and debugging capabilities are very limited, if even included at all. And, unlike with Docker on the container side, no toolchain really is considered the standard to build unikernels. If you’re interested, check out the “Hello World“ for the Unikernel project MirageOS as an example.
Nabla Containers
Nabla Containers is an IBM Research project and uses the Unikernel approach in combination with some other tools to provide a way to run special Nabla images with a container runtime that is OCI-compliant.
First, let’s examine the Nabla containers themselves. These consist of three layers: The application itself, all the necessary OS components bundled in a unikernel system like MirageOS, and, below that, solo5, a general execution environment for several unikernels and hypervisor types. It was specialized for Nabla to implement a very interesting feature: Only seven system calls are used between the container and the host. All other calls are handled in the user space of the container, which minimizes the possibilities for attacks. Because of the setup with unikernel approach, the image format is not OCI image-spec compliant.
To run Nabla containers in your nice, standardized toolchain anyway, the project provides runnc. No, it’s not a typo, that’s runnc with two ns. The name is no accident: This runtime is supposed to be a drop-in replacement for runc, and is therefore OCI runtime-spec compliant. This means that you can continue to use your current toolchain, whatever it may be, up to the point where runc would start a container. runnc takes over and starts a Nabla container.
As simple as that may sound, there are some limitations. For example, even though the runtime is compliant, the images are not. So for you to use Nabla, you’d have to build new containers for all your applications. In general, the project should be considered experimental or alpha, as a lot of desired features are still missing.
Kata Containers
Kata Containers is an OpenStack project. Just like the Nabla project, Kata provides a runtime that fulfills the OCI runtime-spec, it’s called kata-runtime. Unlike Nabla, Kata Containers actually can run OCI image-spec compliant containers, which means you don’t need to touch your existing Dockerfiles. To achieve this, Kata uses a complex chain of tools.
As every container is started inside a new VM, Kata provides an optimized base VM image to speed up boot times for them. Commands like docker exec still need to work, so an agent (located inside the VM, running and monitoring the application) communicates with a so-called kata-proxy located on the host through the hypervisor (QEMU in this case), passing back and forth information from and commands to the container. If you’re interested in the detailed setup, have a look at the architecture documentation.
Kata also supports CNI, which makes it compliant to all major standards while still running the actual containers in a VM.
Firecracker
Firecracker is Amazon’s answer to the challenge of running strongly isolated customer workloads in the cloud, especially in the Function as a Service (FaaS) area. The project has been featured in Adrian Coylers Morning Paper. To cite from the official website:
Firecracker is a virtual machine monitor (VMM) that uses the Linux Kernel-based Virtual Machine (KVM) to create and manage microVMs. Firecracker has a minimalist design. It excludes unnecessary devices and guest functionality to reduce the memory footprint and attack surface area of each microVM.
Firecracker provides a virtualization environment that can be controlled via an API. Every microVM provides minimal storage, networking and rate limiting capabilities that the guest OS can use. Essentially, Firecracker is a Virtual Machine Manager like QEMU.
You see that Firecracker itself doesn’t touch the standards I use for comparison throughout this post. Nevertheless, efforts are being made to e.g. use Firecracker as the VMM for Kata containers instead of QEMU. This would mean bringing together the adherence to the necessary standards by Kata with the fast and secure microVMs that Firecracker provides. On top of that, a firecracker-containerd mapper also exists allowing you to use containerd to run containers as Firecracker microVMs. Both approaches are relatively new and should be considered alpha or experimental.
gVisor
Already wondering where Google would come in? Here they are! The Google Cloud Platform also tries to solve the problem of hard multi-tenancy with their very own solution gVisor. It is e.g. used in GKE sandbox and its features may sound familiar to you: It sits between the application and the host, narrowing down the number of syscalls made to the latter by handling the others in the userspace—just like Nabla.
The main components of gVisor are Sentry, Gofer and runsc (I bet you know what that means). Sentry is the central user-space OS kernel that the untrusted application uses. It handles most of the syscalls and every application or container that you hand over to gVisor gets its own instance. For Sentry to be able to access the file system in a secure manner, Gofer is used. And, finally, for you to run your applications on this stack, there is runsc. As you might have guessed, this means that it implements the OCI runtime-spec—regular Docker images and other OCI images will just run, with only minor limitations as not every system call, /proc or /sys file is implemented.
To use gVisor in a Kubernetes setup, you can either use the containerd-shim provided or work with the Runtime class again, as I described for containerd earlier.
That’s a wrap on our VM-based runtimes. Let’s summarize our findings.
Conclusion
By now, you have heard of a lot of container runtimes and your head is probably spinning. Especially, all the names can be really confusing: Kata, Nabla, containerd, runc, runnc, runsc, Sentry? Come on. I only got one more for you:
CRI-O
As the name gives away, CRI-O (or crio) primarily implements CRI. It is intentionally developed as a lightweight container runtime especially for Kubernetes. The essential part: It can work with any OCI runtime compliant software, like runc or kata-runtime. So in principle, it functions as an omnipotent mediator between Kubernetes and diverse runtimes of your choosing.
This means you can get really creative combining different solutions: As e.g. runsc (that was gVisor’s runtime) adheres to the OCI standard, you can use CRI-O instead of the proposed containerd workflow. Be warned though: Not everything that is theoretically possible should also be done. As mentioned earlier, extra steps add instability, which is one of the main reasons Docker is eliminated from a growing number of Kubernetes setups.
I chose to put crio in the conclusion part because it arches back nicely to the beginning, where I laid out the groundwork for this post with OCI, CRI and CNI.
Comparison
I’m sure you know that there can be no recommendations or winners here. The container jungle is complex, ever-changing and rapidly growing. Sometimes, it’s hard to keep track. With this overview, I wanted to raise awareness for mostly one argument: It doesn’t always have to be Docker. And also, Docker is not Docker, but rather a stack of independent parts that can be used in combination with a lot of other interesting projects. Especially if you’re facing the challenge of untrusted workloads and/or strict multi-tenancy in your cloud infrastructure, VM-based solutions might be worth a closer look. If you scrolled down here real fast to get to the executive summary, here goes:
- No matter if you’re using Docker or containerd, runc starts and manages the actual containers for them.
- Rocket (rkt) is dead.
- Singularity is a special container runtime for scientific and HPC scenarios.
- Nabla (IBM-backed) and Kata (OpenStack project) both provide a way to run applications in VMs instead of containers. For Nabla, you have to build a special image to do so, based on Unikernel technology. Kata can handle OCI-compliant images, meaning you can use regular Docker images.
- Firecracker (open-sourced by Amazon) is a VMM that runs so-called microVMs. There are efforts to use Firecracker as a replacement for QEMU with Kata containers, which could combine the advantages of both.
- gVisor by Google uses a technique similar to Nabla, reducing the number of syscalls made to the host system; creating an enforced trust boundary between the application and the host.
- CRI-O maps the Container Runtime Interface of Kubernetes to the OCI runtime-spec. This enables you to create all sorts of wild runtime combinations in your cluster.
That was a lot of input, and I hope you—just like me, writing this—learned a bunch. If you want more detailed insights on your particular setup and its pros and cons, let us know in the comments. We’re always up for a good challenge!



Thank you for time to write this article, was really useful.
thanks this is very helpful
Thank you for this article. Very clear and it gives the right amount of informaiton for lost people.
Thank you for detailed explanation! Hope to see more useful articles.
Awesome summary. Detailed write up providing an excellent overview.
Very useful! Thank you.
Hi Simon,
This is one of the best reviews along with the Net I’ve read!
Thanks for your time and great article.
Thanks for the article. I would highlight that Kata isn’t just QEMU — take a look at Kata with Cloud Hypervisor and Firecracker, too. Nice summary!
Excellent summary!