
Notice:
This post is older than 5 years – the content might be outdated.
Microservice architecture is one of the buzzwords that has notably influenced software development in recent years. This influence went as far as basically branding the term ‘monolith’ as a bad practice. Monoliths seemingly have to be avoided at all costs and microservices, therefore, appear to be inevitable. That’s why many projects start with this architecture from the very beginning if they have the possibility. Some longer living systems are being rebuilt or restructured to follow this approach as well. But this process is often more difficult by quite a lot.
At inovex we obviously talk about this approach to building systems quite often, and we did so during this exemplary project: The following article is about whether, when, why and how we moved a pre-existing monolithic system towards a microservice structure. Our intention is to help you better understand the implications and possible risks of such an introduction with empirical values, i.e. real-world experiences.

This article covers the migration of a non-greenfield project. Our project revolves around a pre-existing system, which has to continue running during the migration process. In addition, we have some technical and organisational constraints. We will not cover the basics of what microservices are and presume at least a rudimentary understanding of the implications of this architectural type. There are plenty of sources out there that explain this concept in-depth very well and cover the (dis)advantages of building microservice systems.
This is a Series of Blog Posts
This article is the result of a project that started more than three years ago and is still ongoing. As you can imagine a lot happens in such a timeframe, which is why we have divided the article into several parts:
- This is the part you are currently reading. We’ll give you an introduction to the reasons that caused us to consider a change. We also show the status quo that existed before our migration towards a more microservice-oriented architecture.
- The second part contains the description of everything that changed and parts of the setup that did not change (yet). This includes some of the reasons for the specific actions we took and those we skipped.
- The final part sums up the whole project: We draw conclusions about what changed for the better or worse and whether we recommend anyone else to follow the path we took during the past year.
Why is There a Monolith at All?
Clearly, the initial decision for the architecture of this project was to go with a monolithic application. To better understand this choice, we want to have a look at our goals for many projects that start on a greenfield. Most of these projects start out as MVPs or POCs with very limited time and budget frames. Additionally, the requirements for those systems rarely contain the expectancy of a big number of users (>=10.000) once the platform goes live at some point. The expected long term scaling of such systems is rather small as well.
Especially at the beginning, we try to keep the complexity of those products as low as possible. Often, a project is implemented according to startup ideas: reach a result with a minimal set of initial features in as little as possible time spent. As a result of this, there may even be quick & dirty solutions that are sustainable for the moment but will have to be replaced one day.
Yet you keep asking yourself whether it might be worth following the microservice pattern. This is also the case in this project. We discussed the question explicitly in the team at the beginning of the project (size: 2–3 developers in the first 18 months for backend, frontend and mobile). We decided against it because we had to expect disadvantages in operations, error analysis and stability due to the increased complexity and the distributed architecture.
Other Projects
In other projects, however, we try to make big decisions about design and technology for the coming years right at the beginning. Over-engineering usually plays a major role here and in the first few months, you are often more occupied with the technological side of things than with functional features anyway. Experience shows time and again that it is completely sufficient to make decisions based on the most pressing current challenges and problems. It is not necessary to design each action completely decoupled and asynchronously right from the beginning. Asynchronicity itself causes complexity in many aspects.
One example of this is the delivery of emails. If we were to send important emails asynchronously, e.g. those confirming the registration, we would at least have to implement a simple retry and queuing mechanism. We opted for the synchronous variant because the implementation effort was significantly lower. In addition, we did not need a highly available, error-tolerant and highly scalable solution.
Status Quo: “in-between“
During the first year, our setup turned out to work very well. The service was easily maintainable and we didn’t run into serious problems with the monolith solution. Only singular, very small parts were built into additional separate applications. Those parts treated very different issues and also needed to be deployed independently to additional hosts and/or regions. Many of those services shared a single database which still meant an extensive degree of coupling.
Another aspect that was very straight forward in the context of a monolithic system was testing. Integration testing did only require dependencies like a database to be executed with the tested application. End-to-end testing was quite easy as well since backend and frontend were packaged into one build file and distributed together. So, if everything was marvellous, why did we think about changing the existing system?
Why we needed a change
In time we met changes and therefore new requirements for the system that demanded some form of change.
Team Constellation
One of those changes interestingly concerned the team, which grew considerably over time. This obviously meant that more people were working on the project simultaneously. They were mostly distributed over different features and parts of the application (such as a split between backend, frontend and mobile applications). Having more people on the team means more changes to the system coming in at any given time. This includes various side effects on other parts of the system caused by a change. That way some initially seemingly small features can become quite complicated since they have an impact on existing features. This requires further changes to the existing codebase which again might interfere with the work of a colleague being done at the same time.
Team Growth

The growth of the team also meant that we had to address the issue of distribution of knowledge among the team members in two ways, the first of which is sharing knowledge. New members of the team did not have the same deep knowledge of the application as the old team did. Yet one of the obvious goals that come with building a bigger team is to share as much knowledge as possible with your team members. Especially the goal to make the team itself and their development progress more tolerant to single developers being unavailable at any given time. Learning about the existing code base, all its features and system-internal dependencies was made a lot more difficult by the huge scope of the single monolithic application, especially with only very little and somewhat blurred separation of features.
Of course, the opposite of this would have been cleanly cut microservices where each service caters to a singular functional concern. Implementing new features or extending existing ones included an extensive amount of explaining or looking for code that would be affected by side effects. The result of all this was an increased risk of failure with every deployment of the big monolithic application.
What Made it Easier
What actually helped a lot to notice side effects was a good test coverage of the application. This includes integration testing and end-to-end tests. The automatic test pipelines are able to discover most of breaking changes before they were deployed anywhere. From time to time some mistakes made it into the productive system anyway of course. The search for bugs was also hampered by the big monolithic application and the tight coupling of components. Extensive logging of both successful actions and errors was of essence in this scenario.
The second issue connected to team growth was knowledge lying with single developers instead of being distributed across multiple members of the team. This again would lead to the team at least being held back in their capacity to react to bugs or to continue development on specific features. More so if the one person holding this specific knowledge would be temporarily or permanently unavailable.
The New Stuff
New Features
With the progress of the project, two types of new features came along. One of those could be matched with the then-present application. The extensions of the existing application alone made up a considerable amount of required additions to the monolith. This implied the risk of necessary changes becoming too big due to an already huge codebase. At this point, some version upgrades were already assessed as being too risky or too big to address for the time being. The second type of new features belonged to a new domain that was well separable from the then-present application. Both of these circumstances together strongly indicated the benefits of new services. Services with their own functional domains instead of the continued extension of the already quite big application.
New Tech
Another factor for the decision to start moving towards microservices was the developers‘ interest in newer technologies and the eagerness to keep the product up-to-date with recent updates. The upgrade to new major versions of essential technologies like Spring Boot turned out to be both quite difficult and risky. By separating the system into multiple services, major version updates were expected to become easier. Experience on how to set up the new major versions could be gathered within newly set up services as well.
What Could go Wrong?
From the beginning we expected some aspects like testing that were quite easy before to become more complex. Since we also knew about the benefits mentioned before this could not stop us from moving towards a microservice architecture.
Right before the migration
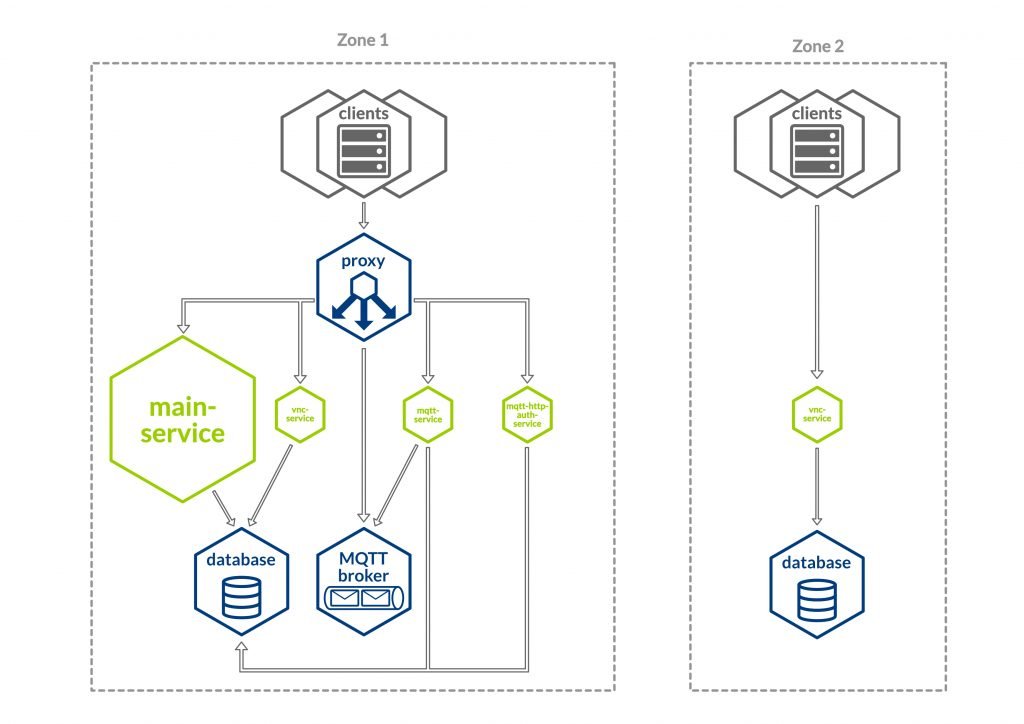
Before we took the first steps of the migration, we had four services. Four of those are very small and only contain small singular technical features. Additionally, we have one monolithic application that encompasses all remaining functional features. On top of that we have the following architecture:
- There are four applications/services in total
- The main application in its monolithic form
- mqtt-http-auth-service: handles the authentication for the message broker
- mqtt-service: listens to a subset of special messages on the message broker and writes those to a database
- vnc-service: small independent service that had little to do with the rest of the application and served a purely technical purpose
- Services do not need to communicate with each other, but there is some data that is read from or written to the database by multiple services
- Our DBMS is built with multiple tables inside one single database that is shared between all the services
- The static (SPA) frontend lies within the main application’s WAR-file and is therefore deployed alongside the monolithic backend. The other services do not depend on the frontend.
- There are integration tests on the API endpoints and end-to-end tests with the frontend. Both can be executed on the single applications‘ build output from within the CI pipeline
- An MQTT Broker for messages between our services and a number of external IoT devices
Coming up next
This is it for now. You should know about our reasons to go for the microservice architecture and also our expectations for this change.
In part 2 of the series we will talk about the actual changes that have been made. But we will also shed light on the steps we intentionally did not take when leaving our monolithic system behind.
All pictures except title are taken from Unsplash.


