
Data quality (DQ) is a critical concern in today’s data engineering. Poor data quality directly impacts the reliability of models, reports, and overall trust in data products (garbage in, garbage out). Consequently, the conversation shifts from the necessity of DQ to the specific frameworks required to implement it effectively.
Many teams initially adopt established frameworks. While effective, these frameworks can present challenges including a potentially steep learning curve, considerable configuration overhead, and a business model that pushes you to buy the enterprise product.
This post explores a lightweight alternative: DQX – A framework we used to implement a data quality monitor.
The Established Frameworks: Great Expectations & Soda
Before exploring lightweight frameworks, let’s address the elephants in the room: Great Expectations (GE) and Soda. These are powerful, popular frameworks, but it’s important to understand their structure and the overhead they can introduce.
A common point of confusion is the difference between their core open-source libraries and their enterprise platforms.
- Great Expectations Core vs. Great Expectations Cloud: GE Core is the open-source Python library for defining “expectations“ (data quality checks). Expectations are defined directly in the Python code and can be saved and read in as JSON. The paid GE Cloud SaaS is a fully hosted, collaborative platform that builds on this open-source core. It adds a UI to manage your expectations and enterprise features for data governance.
- Soda Core vs. Soda (Cloud/Enterprise): This is a similar story. Soda Core is the open-source, command-line tool and Python library used to define and run data quality checks. In Soda, checks are defined in SodaCL, a YAML-based soda-specific domain language. The paid Soda Cloud SaaS platform is the enterprise-grade product built on top. It provides a UI, dashboards, and advanced alerting, none of which are included in the open-source core.
Core vs. Enterprise
While the core libraries are free, using them effectively in production often requires significant custom code. This is most apparent with custom checks, which can be used to write additional checks that are not present in the pre-defined checks each framework comes with. Both Great Expectations (GX) and Soda allow for custom SQL. But they hit a wall regarding reusability in their open-source versions:
In GX Core, developers must write SQL queries to implement their custom checks. Developers can’t reuse them with different parameters for other tables and columns. They will need to come up with their own solution. In the paid cloud version, there are some more features available: For example a UI to add some parameters for row filtering.
In Soda Core, custom checks are also implemented as SQL queries in SodaCL. To reuse them for other tables or with other parameters, there is a feature named templates available in the paid Soda version. This is somewhat counterintuitive, as Soda Core offers parameterizable pre-defined checks out of the box. Consequently, without the paid version, developers are forced to implement their own custom solution.
Limitations like these can lead to teams writing a lot of custom code to work around the frameworks‘ limitations, sacrificing productivity to manage this custom-built overhead. The experience can feel like a constant, low-level pressure to upgrade to the paid SaaS platform rather than enabling effective use of the core library.
🚀 A Lightweight Champion for Databricks: DQX
For teams working within Databricks, there’s an excellent alternative to the established frameworks: DQX by Databricks Labs. DQX is an open-source framework engineered specifically to handle data quality within the Databricks environment effectively.
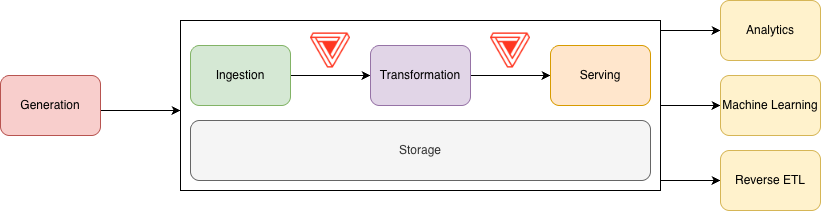
Data Engineering Lifecycle with DQX (adapted from Reis & Housley, 2022)
Unlike Databricks Pipeline Expectations which can be a great choice for pre-persistence checks in Spark Declarative Pipelines — DQX can be used in the entire data engineering lifecycle. DQX can perform both pre- and post-persistence checks, enabling developers to implement a solution that truly fits their needs.
The core design philosophy of DQX centers on overcoming common challenges associated with implementing data quality checks. DQX main advantages are the following:
- Easy integration and configuration: DQX is designed for a low-friction setup within Databricks. The goal is to get teams from installation to writing their first checks as quickly as possible, without a lengthy configuration cycle.
- Extensibility with custom checks: While pre-built checks are useful, every data has unique business logic. DQX allows teams to write their own custom data quality checks using PySpark functions. This is a significant advantage for data engineers and data scientists who are already comfortable in the Spark ecosystem, as it allows them to define complex, domain-specific validation logic without leaving their familiar environment.
- Automated rule suggestion: DQX includes a profiler. This feature analyzes a dataset to understand its characteristics (e.g., data types, value distributions, nullability). Based on this profile, it automatically suggests a baseline set of data quality checks, which teams can then accept, reject, or refine. And yes, you can also do this with AI.
- Dashboards: DQX comes with a pre-configured Databricks Dashboard. This is a great starting point for your data quality monitoring.
- Performance: Engineered specifically for Databricks, it integrates seamlessly with PySpark and the platform’s core features to ensure speed and efficiency.
💻 Implementation
Data quality checks in DQX can be defined in various ways: as DQX classes in Python code, as delta table, or in a separate JSON or YAML file using a DQX-specific domain language. This example demonstrates the use of the domain specific language expressed in YAML syntax. The implemented check (is_not_null_and_not_empty) is a predefined checks that checks column city for null or empty string values.
|
1 2 3 4 5 |
- criticality: error check: function: is_not_null_and_not_empty arguments: column: city |
For a quick start, DQX can be installed in a notebook.
|
1 2 3 |
%sh pip install databricks-labs-dqx dbutils.library.restartPython() |
We demonstrate the check by loading the samples.bakehouse.sales_customers dataset and setting city for row with customerID=2000259 to None. After initializing the data, we apply the check defined in the checks.yml file to the DataFrame to identify the intentional error.
|
1 2 3 4 5 6 7 8 9 10 |
from databricks.labs.dqx.engine import DQEngine from databricks.sdk import WorkspaceClient input_df = spark.read.format("delta").table("samples.bakehouse.sales_customers") input_df = input_df.withColumn("city", when(col("customerID") == 2000259, None).otherwise(col("city"))) dq_engine = DQEngine(WorkspaceClient()) checks = dq_engine.load_checks_from_workspace_file(workspace_path="./checks.yml") result_df = dq_engine.apply_checks_by_metadata(input_df, checks) result_df.write.format("delta").mode("overwrite").saveAsTable("unity_catalog_path") |
The resulting DataFrame result_df has two new columns: _errors and _warnings. As the level of the check is error, the _errors column in result_df for the row with customerID 2000259 contains a JSON with the error information.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[ { "name": "city_is_null_or_empty", "message": "Column 'city' value is null or empty", "columns": [ "city" ], "filter": null, "function": "is_not_null_and_not_empty", "run_time": "2025-07-09T08:56:11.080262Z", "user_metadata": {} } ] |
This information can be used to filter your dataset and to build data quality monitoring based on passed and failed checks. One low-hanging option is to visualize the information in a prebuilt Databricks Dashboard that DQX comes with. It offers an immediate overview of data quality by charting failure percentages alongside a comprehensive table of failing checks.
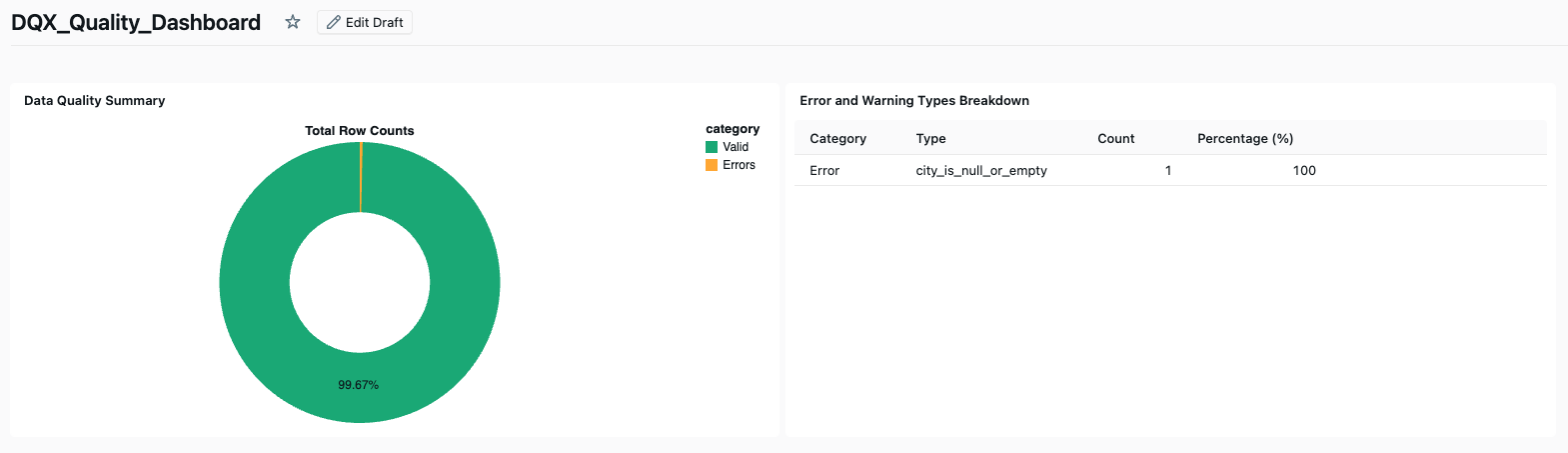
DQX prioritizes performance by focusing primarily on row-level checks. This means some features found in established frameworks, like full-table distribution checks, aren’t part of its features.
Examples for more complex custom checks, applying the same check on multiple columns, how to add more metadata to checks, and how to use the profiler to generate rule recommendations automatically can be found in the DQX documentation. In the end, you probably want to persist your data quality runs and build filters and custom monitoring that fit your needs.
Final Thoughts: Choosing Your Data Quality Framework
Before committing to a costly enterprise platform or spending weeks customizing a big framework, step back and evaluate your team’s actual needs. Often, a fast, integrated solution is the better choice.
For data quality in Databricks, DQX stands out by offering high performance with low overhead. It strips away the complexity of heavier frameworks, leaving you with a tool that is fast, flexible, and easy to manage.


