
Nowadays, access to high-quality real-world data has a major impact on the success of data-driven projects, as the quality of a Machine Learning solution strongly depends on the available training data. On the other hand, data owners are often not in a position to share their data because it may contain sensitive information such as company secrets or personal information subject to the GDPR. Federated Learning enables to use sensitive data for the purpose of Machine Learning while preserving its privacy and without revealing any information about it. This blog post explains how Federated Learning works and what privacy techniques are necessary to ensure that sensitive data is protected. A basic knowledge about Machine Learning is required to understand this blog post and can be acquired at „Deep Learning Fundamentals: Concepts & Methods of Artificial Neural Networks“ [1] if necessary.
Federated Learning = Differential Privacy & Secure Aggregation & Federated Averaging
Federated Learning combines the known schemes of Distributed Learning with the techniques of Differential Privacy, Secure Aggregation and Federated Averaging. This combination enables to train with the sensitive data of collaborating participants. It can be applied with any participant holding secret information. By allowing to learn from distributed data in a privacy preserving way it opens a wide range of use cases for solving problems with previously unusable data.
Foundations of Federated Learning
Federated Learning enables training on sensitive data of multiple data holders without sharing the data itself. Participants holding data of the structure and semantics take part in the federated training process to collaboratively train a model. Here are some examples giving an idea about possible areas of application:
- Owners of production machines contribute their sensitive machine production and downtime data to the training of a predictive maintenance model
- Hundreds of smartphones participate in the training of a text auto-completion model by contributing their actual text input
- Multiple hospitals train an enhanced tumor-detection model by using brain x-ray images of their patients to collaboratively train a model
These are just a few examples of Federated Learning enabling the use of sensitive data for the purpose of Machine Learning. A participant can be any device able to run Machine Learning and communicate with a central curator. In these examples, the training takes place on the production machines, smartphones or hospital servers.
By training federated on decentralized data, Federated Learning comes with privacy by design. The data used for training is never moved from those devices or sent to a central location, as with centralized Machine Learning, but remains on the participant hardware. In Federated Learning, models (more specifically model updates) are exchanged between the participants and a curator that manages the Federated Learning process. This process is visualized in Figure 1 featuring three participants in green, blue and red collaboratively training a central model. Initially, a central model architecture is defined and the parameters of the model are randomly initialized. Subsequently a Federated Learning itteration is run by executing the following steps:
- A copy of the central model is distributed to all participants replacing their current local model.
- Each participant trains the received central model with its own local private data using Differential Privacy. This yields an updated local model.
- The updated local models of all participants are aggregated to a new central model by a curator using Secure Aggregation and Federated Averaging.
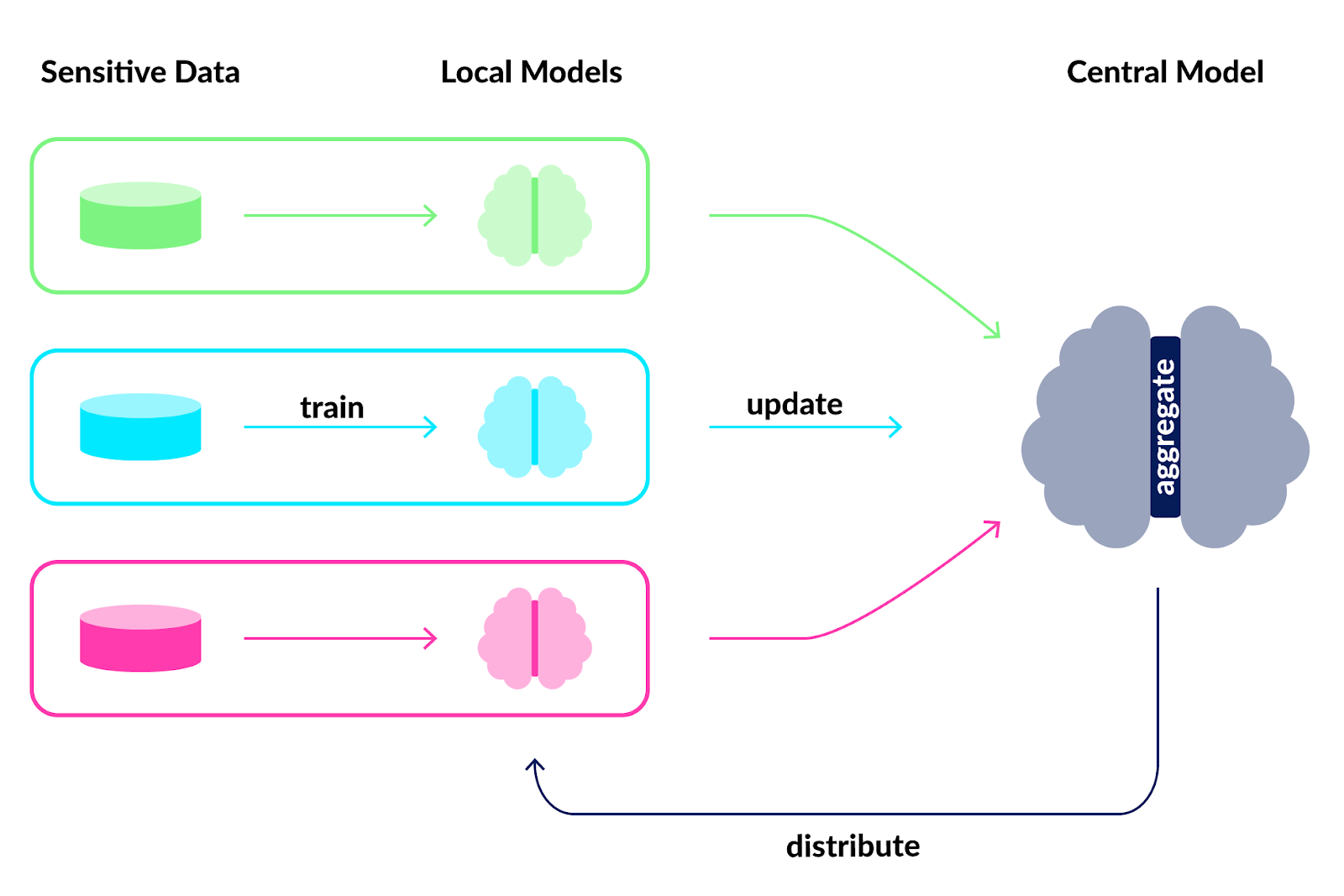
This Federated Learning process is repeated until the central model reaches a sufficient accuracy or a privacy budget is spent. The next sections will clarify what sufficient accuracy or a privacy budget in context of Federated Learning means. Federated Learning evolved from Distributed Machine Learning with additional use of techniques called Differential Privacy, Secure Aggregation and Federated Averaging. All of these key techniques will be explained in the following.
Differential Privacy: About the Memory of Machine Learning Models
Models trained by Machine Learning should learn generic patterns and regularities of the training data and not just memorize specific training samples. But it is possible, that models save information about individual training samples in their parameters. Third parties could attack the model to extract the underlying training data. Thus, it must be ensured that the models cannot leak any sensitive information when shared in the process of Federated Learning. The following example illustrates that a model can save such information and how this information can be extracted without requiring complicated algorithms. Imagine using your Android keyboard which has been trained with Federated Learning on actual user keyboard input as described in [2]. When typing “my credit card number is…“ and then get a suggestion for auto-completing a valid credit card number, sensitive information has been ‘extracted’ from the model. In this case the model has unintentional learned personal information from the data set used to train it.

In this specific example, it is quite simple to extract data from a text auto-completion model on accident. But there are techniques which aim to reconstruct data from all kinds of models. One of those are Generative Adversarial Networks, which can be found out more about at [3].
To prevent models to be attackable by any kind of algorithm, Differential Privacy must be applied during the training process. By including it into the trainings process, for example in stochastic gradient descent, the model does not even learn the characteristics of a single sample but only the patterns and regularities of the overall samples. To reach that goal, Differential Privacy perturbes the model by adding noise to the parameters. The noise is scaled in such a way that the model cannot hold any information about an individual sample but just the generalization over all samples.
By including Differential Privacy in the local training of the participants, it is ensured that the model is protected against data extraction attacks before it is even sent to the curator. Thus the curator cannot attack the model of the participant. Furthermore the aggregated central model also does not include any information about individual training samples. Unfortunately this has some disadvantages: The generalizing of the parameters AND the privacy budget that limits the number of training iterations can lead to poorer model accuracy. The privacy budget determines how strongly the local models are perturbed by Differential Privacy and how many training epochs are possible before leaking sensitive information. It must be chosen to ensure both: A sufficient privacy by avoiding the reconstruction of training samples AND a sufficient accurate model. Differential Privacy is a mandatory privacy technique that must be included in all Federated Learning processes to ensure the privacy of sensitive training data of the participants.
Secure Aggregation: Anonymity in Federated Learning
With Differential Privacy the reconstruction of training samples can be prevented. But by taking a closer look at the model parameters, general conclusions about the underlying training data still can be drawn. The curator in Federated Learning needs access to all the local models for the purpose of aggregating the new central model. Therefore it can analyze the local parameters for further information about their underlying data like in the following example: In a scenario of collaboratively training on medical data from multiple hospitals, it can be deduced that a hospital, whose local model greatly improves in the prediction of heart attacks, most likely has a lot of unhealthy patients. As a consequence the health insurance contributions in the area of the corresponding hospital could be raised. Thus it is very important to ensure that parameter changes cannot be mapped to a participant. Secure Multi-Party Computation (SMPC) is a protocol to execute secure calculations in order to publish the result only to a single instance while guaranteeing that the values of the calculation are not known to anyone but the contributor itself. Therefore the parameters of all participants can be aggregated without knowing their actual contribution to the aggregated result. The curator only receives the resulting combination of all local models but not the values of a single local model. Visa versa, they cannot spy on a single model when only receiving the combined data. In general, SMPC is a mandatory technique required to ensure privacy in Federated Learning, unless the data owners decide to trust the curator not spying at their data, or even decide that the general nature of their data does not need to be protected from the curator.
Federated Averaging: Aggregation of Models
The usual way of aggregating models in Distributed Machine Learning assumes that all participants hold the same number of training samples. However, in Federated Learning, participants are likely to hold an unequal number of data. To account for this, the local models are aggregated by weighting each local model by the number of available training samples as depicted in Figure 3.
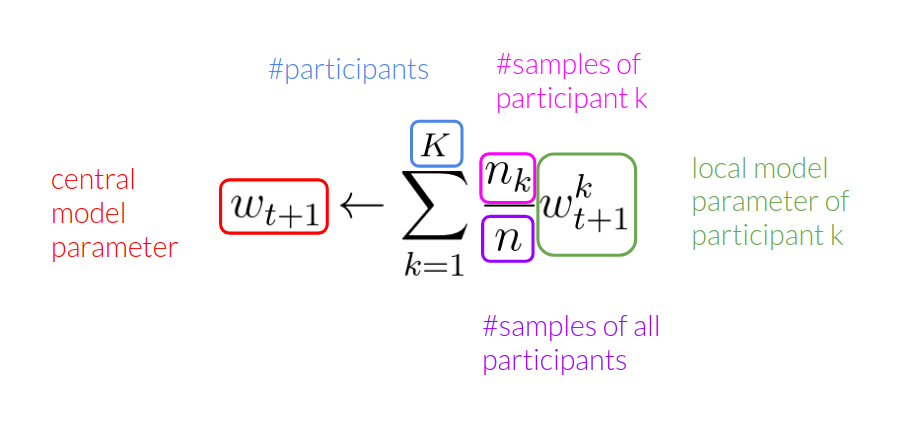
Thus models of participants holding higher number of samples are taken into account more than the once holding just a few. While this strategy does sound very simple, it has shown to work very well in Federated Learning use cases [4].
Model Validation in Federated Learning
In Machine Learning, accuracy is a measurement of how accurate a model can predict a set of sample data. It is defined as the ratio of the number of correct predicted samples to the total number of samples. In Deep Machine Learning, the accuracy is monitored while training to observe if the model is improving using a separate validation dataset. After training the model is tested by evaluating the accuracy using an additional test data set. The training-, validation- and test data are distinct subsets of the overall available data. Because in Federated Learning the training data remains local to the participants, the central curator cannot calculate an accuracy using any of the subsets. Thus to determine the quality of a model requires some additional preparation. Usually the curator holds some data samples that come from the general distribution of training data, and the central model can be validated and tested with this data. These samples would not be sufficient to train a model with but can be used for the purpose of testing and validation. This may be a synthesized subset, some sample data which are not subjected to privacy constraints or sample data collected by the curator.
In another approach the participants evaluate the central model on their local data and average their accuracy by using Secure Aggregation. By using SMPC the privacy of a single participant is not compromised, but only the average over all participants accuracy is revealed.
Conclusion and Where to go From Here
Applying distributed learning on sensitive data from multiple sources with the privacy preserving techniques of Differential Privacy and Secure Aggregation enables to train models without revealing any secret information about the individual training data of any participant. A successful training is ensured by aggregating the local models weighted by their number of training samples to a central model. This central model then learned the structures and regularities of all participants data. If you are interested in applying Federated Learning in your own project stay tuned for the next article of this series about Federated Learning frameworks!
Acknowledgements
This blog post covers the foundations of Federated Learning and its underlying techniques. The research behind this started in my bachelor thesis „Evaluation of Federated Learning in Deep Learning“ at inovex Lab and meanwhile takes place in the research project „KOSMoS – Collaborative Smart Contracting Platform for Digital Value Networks“, where we currently implement Federated Learning for predictive maintenance based on production machine data [5],[6]. The research project is funded by the Federal Ministry of Education and Research (BMBF) under reference number 02P17D026 and supervised by Projektträger Karlsruhe (PTKA). The responsibility for the content is with the authors.
References
[1] Patrick Schulte (2019) Deep Learning Fundamentals: Concepts & Methods of Artificial Neural Networks
[2] Carlini, N., Liu, C., Erlingsson, Ú., Kos, J., & Song, D. (2019) The secret Sharer: Evaluating and testing unintended memorization in neural networks
[3] Hitaj, B., Ateniese, G., & Perez-Cruz, F. (2019) Deep Models under the GAN: Information leakage from collaborative deep learning
[4] Brendan McMahan, H., Moore, E., Ramage, D., Hampson, S., & Agüera y Arcas, B. (2017) Communication-efficient learning of deep networks from decentralized data
[5] Marisa Mohr, Christian Becker, Ralf Möller, Matthias Richter (2020) Towards Collaborative Predictive Maintenance Leveraging Private Cross-Company Data
in press in: Lecture Notes in Informatics, 2020, Gesellschaft für Informatik e.V., Bonn, Vol.307, 2020.
[6] Christian Becker, Marisa Mohr (2020) Federated Machine Learning: über Unternehmensgrenzen hinaus aus Produktionsdaten lernen


