
This article provides an introduction to privacy-preserving record linkage (PPRL), a process that allows organizations to link records from different sources while maintaining data privacy and confidentiality. It discusses the challenges of applying PPRL to Big Data, including privacy, scalability, and linkage quality. It then outlines the steps involved in the PPRL pipeline and describes the methods used to evaluate the correctness and privacy of the pipeline. The article aims to provide a high-level overview of PPRL for researchers and practitioners interested in applying it to real-world applications.
The Big Data revolution has enabled organizations to collect and process datasets with millions of records to uncover patterns and knowledge to enable efficient and quality decision-making. Matching and linking records from different sources to improve data quality or enrich data for analysis is used in government services, crime and fraud detection, national security, healthcare, and other business applications. Matching and linking records have also been important in generating new insights for population informatics in the health and social sciences.
Safeguarding sensitive information in record linkage across organizations
Within a single organization, the entity matching process generally does not involve privacy and confidentiality concerns, as long as the linked data are not revealed outside the organization. Using entity matching techniques to deduplicate a product database to achieve better quality in analytics or to deduplicate a customer database for marketing activities are two examples.
The use of data from multiple organizations to match results can reveal sensitive or confidential information not present in any single organization’s database. If not handled with care, this can lead to a leak of information such as medical details of high-profile individuals, or inconclusive criminal implications, which can have a major impact on individuals‘ lives. Additionally, entity matching across organizations may not be allowed due to laws or regulations, such as the General Data Protection Regulation (GDPR) in Europe and the Health Insurance Portability and Accountability Act (HIPAA) in the USA.
Entity matching or record linkage is a common data processing task that aims to link and integrate records that refer to the same entity from two or more different data sources. When linking data, record pairs are compared and classified as „matches“ or „non-matches“ by a model (see the previous blog post for more details). Matching/linkage requires sophisticated comparisons between a set of partially identifying attributes (also known as quasi-identifiers or QIDs) such as names and addresses. Unfortunately, these QIDs often contain personal information which makes it impossible to reveal or exchange them due to privacy and confidentiality concerns.
Privacy requirements in record linkage processes have been addressed by developing ‚privacy-preserving record linkage‘ (PPRL) techniques. These techniques aim to identify matching records from different databases without compromising the privacy and confidentiality of entities. In a PPRL project, data owners agree to reveal only selected information about records classified as matches. Therefore, the linkage must be conducted on masked (encoded) versions of the QIDs to protect the privacy of entities. Various masking methods have been developed, which can generally be classified as secure multiparty computation or data perturbation-based methods.
Leveraging Big Data’s tremendous opportunities brings challenges such as scalability, quality, and privacy. Data volumes and flows at Big Data scales make scalability difficult even with advanced distributed computing technology. The variety and veracity of Big Data also add challenges to the linkage process. With immense personal data, linking and mining can easily breach data privacy. Therefore, a practical PPRL solution should address all of these challenges for real-world applications. However, existing approaches for PPRL still do not address all of the Big Data challenges, and more research is needed to leverage the potential of linking databases in the Big Data era.
PPRL techniques involve masking databases at their source and conducting the linkage using only masked data, implying no sensitive data is ever exchanged or revealed to any other party. At the end of the process, the involved parties only learn which of their own records match with high similarity with records from the other database(s). The final steps involve exchanging values of certain attributes of the matched records between the database owners, or, depending on the linkage model (see below), sending selected attribute values to a third party, such as a researcher. Recent research in real health data linkage finds that using PPRL instead of traditional record linkage using unencoded QIDs implies only a small loss of linkage quality.
In this article, we first introduce the high-level aspects and challenges of privacy-preserving record linkage. Then, we guide the reader through the identification of the key factors that determine the linkage model and the threat model, which are critical for developing and evaluating the PPRL pipeline. Finally, we discuss the methods necessary for evaluating the correctness and privacy of the PPRL pipeline.
Technical challenges of privacy-preserving record linkage
Key challenges in applying PPRL in the context of Big Data include:
- Privacy: When Big Data containing personal data is linked, privacy and confidentiality must be taken into account. Masking techniques have been used for privacy-preserving record linkage (PPRL), making the task of linking databases across organizations more demanding.
- Scalability: Because the number of comparisons needed for entity matching is equal to the Cartesian product of all the records in the linked databases, comparing all record pairs is a major issue for entity matching because record comparison is a costly operation. With the growing size of Big Data, comparing all records is rarely possible in real-world applications. To counter this issue, blocking and filtering techniques are used to reduce the number of comparisons between non-matching records.
- Linkage quality: Big Data brings the challenge of dealing with variety and veracity (typographical errors and other minor perturbations in data), making matching difficult. Exact matching of QID values, which classifies pairs or sets of records as matches if their QIDs are exactly the same and non-matches otherwise, leads to low accuracy due to data errors. Effective and accurate classification models are needed for record linkage, which facilitates both approximate matching of QIDs and high matching accuracy.
High-level view on the PPRL pipeline
The main general steps of the PPRL pipeline are shown in the figure below. The red arrows are the alternative data flow between the individual steps. The blue rectangles represent computations performed on the encoded/masked QID values.
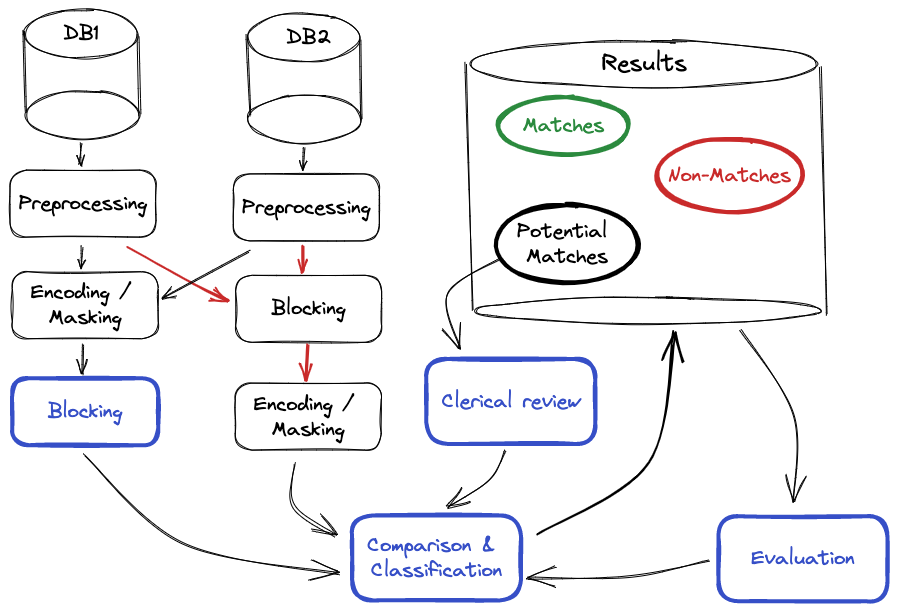
- Data preprocessing is an important step for quality linkage outcomes. Real-world data is often noisy, incomplete, and inconsistent. Therefore, it needs to be cleaned by filling in missing data, removing corrupt or irrelevant values, transforming data into well-defined and consistent forms, and resolving inconsistencies in data representations and encodings.
- Data masking (encoding) is an additional step in PPR that is essential for privacy preservation. All parties participating in the PPRL must conduct the same data preprocessing and masking steps on the data they will use for linking. Exchange of information between the parties about what data preprocessing and masking approaches they use, as well as which attributes to be used as QIDs, is also necessary.
- For more details on blocking and comparison steps in entity matching please refer to the previous blog post on this topic.
- Classification refers to the step which classifies record pairs into non-matches, soft matches (potential matches or when the model is uncertain), and hard matches (matches with high confidence). There are a number of possible classification models including probabilistic, threshold-based, rule-based, and supervised machine learning approaches such as support vector machines and decision trees. Supervised machine learning approaches are usually more effective and accurate but require training data with known class labels for matches and non-matches. However, training data with known class labels may not be available in privacy-preserving settings. In such cases, semi-supervised techniques such as active learning-based techniques can be used. Actively labeling data by experts to train the decision model which selects the most beneficial samples to label minimizes the amount of effort needed for labeling. Advanced classification models such as graph-based linkage can achieve high linkage quality but have not been sufficiently explored for privacy-preserving record linkage yet.
- Clerical review: If the classification process is not based on identifier matching or matching rules which result in 100% confidence, then the samples classified as soft (potential) matches need to be reviewed manually. This process is often prone to errors and costly and depends on the experience of the experts conducting the review. Additionally, a clerical review might not be possible in a PPRL, since the masked QID values cannot be unmasked and inspected due to privacy concerns. However, there are developments of PPRL-compatible interactive methods with human-machine interaction to improve the quality of PPRL results without compromising privacy.
- Evaluation of the complexity, quality, and privacy of the linkage to measure its applicability is the essential final step before the deployment to production. Examples of the evaluation measures have been presented below. However, measuring linkage quality is difficult in real-world applications, since the true match status of the compared record pairs is usually unknown. Evaluating the amount of privacy protection using only standard measures gives an incomplete picture, and such metrics is still an active research field.
Designing a PPRL solution
Developing a PPRL architecture for a specific business use case requires many decisions. To ensure all important factors impacting the architecture are taken into account, one must first determine the Linkage model. Then, the threat model components must be determined. Finally, the evaluation of the PPRL should be planned in advance to define the acceptance criteria of the final solution. The individual steps are shown in the figure below.

Linkage model
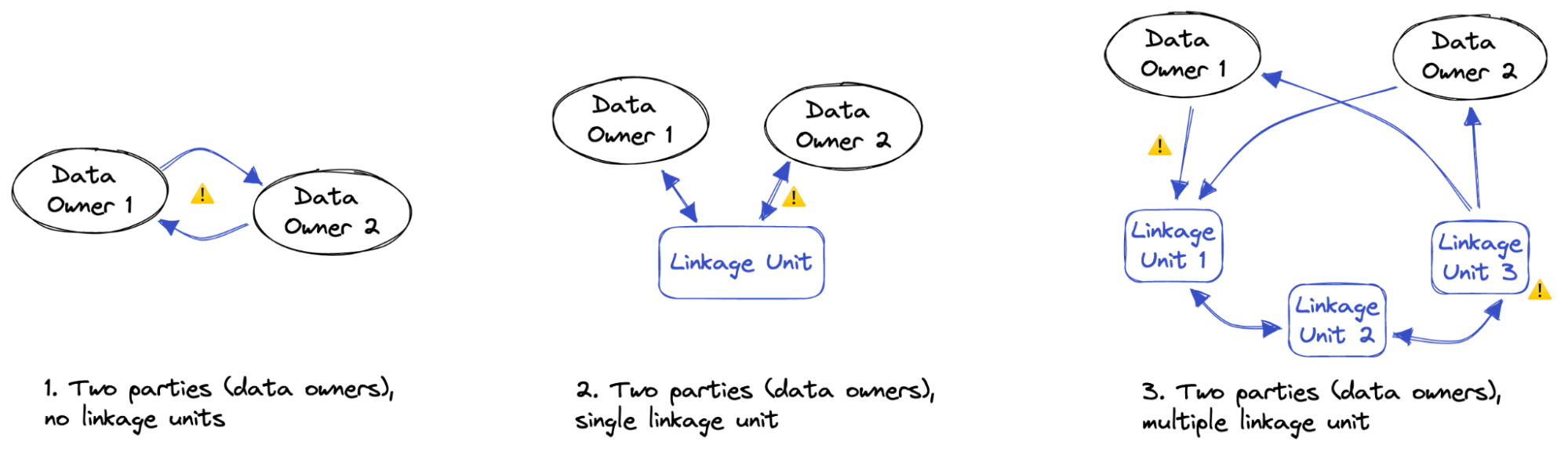
The linkage model is defined on a high level by the number and type of parties involved. We distinguish the different scenarios along the following two dimensions: the number of data owners involved, and the number of linkage units involved. We define the linkage units as the parties who are responsible for applying the matching algorithms but do not own any data.
In two-party protocols, only the two data owners are involved (without any linkage units) with a common goal to identify the matching records in their databases. This setting requires a more complex technique to ensure that there is no possible leakage of sensitive information to any of the parties during the protocol.
To conduct the PPRL a linkage unit is often involved. The obvious drawback of this setting is that it requires a trusted third party to avoid possible collusion attacks, where the linkage unit and one of the data owners collude to expose other data owners’ data.
There are also settings where multiple linkage units are involved. Different responsibilities and tasks of PPRL (such as secret key management, complexity reduction, and matching) are distributed among the involved linkage units. The advantage over the single linkage unit setting is that the separation of tasks across multiple units reduces the amount of available information (and thus the attack surface) to any single linkage unit.
A multi-party linkage setting involves identifying clusters of records from multiple databases that refer to the same entity. Processing can be distributed among multiple parties to improve efficiency and privacy guarantees.
The linkage model is further defined by the schema used for the data during the PPRL protocol. Other than the feature selection, which only impacts the quality/correctness of the entity-matching results, we also need to perform schema matching and optimization between the data sources. It is again important to consider the privacy implication, so the process needs to be performed using secure schema matching.
Threat model
The adversary models of the PPRL systems can be categorized into the following classes:
- Honest-but-curious or semi-honest behavior: This is the most common model used in PPRL studies. It assumes that the parties involved follow the protocol truthfully, while also attempting to gain as much information from the received data as possible. This model has weak guarantees of privacy and robustness to adversarial attacks, due to its unrealistic assumptions.
- Malicious behavior: This model assumes that the parties involved in the protocol may not adhere to the steps truthfully by deviating from it, sending false input, or behaving arbitrarily. It offers improved privacy guarantees but requires more complex and costly techniques to make the protocol resistant to adversarial attacks.
- Advanced adversary models: In this category, we include the models that are a hybrid between the two above-mentioned models such as accountable computing and covert models.
When analyzing the robustness of the PPRL system, one needs to consider the possible adversarial attack scenarios. The most common types of attacks include:
- Frequency attack: In this attack the frequency of encoded values (without knowing the secret key) is mapped to the frequency of known unencoded values, potentially revealing the correspondence between the encoded and available entities.
- Collusion attack: This type of attack has to be considered in linkage unit-based and multi-party models. Here one assumes that a subset of parties colluded to learn another party’s data.
- Algorithm-specific attacks: We also need to consider the vulnerabilities of the specific algorithm we wish to use in our PPRL system. For example, Bloom filters (an encoding that has shown to be an efficient way to encode sensitive information into bit vectors while still enabling approximate matching of attribute values) are vulnerable to cryptanalysis attacks, which allow the iterative mapping of bit patterns back to their original unencoded values based on their frequency alignments.
Evaluation
Criteria for evaluating the PPRL pipeline performance:
- Correctness is the most important quality because it determines the usefulness of the whole system. It is equivalent to the linkage quality aspect and often is measured with precision, recall, area under curve (AUC), and F1-measure of the results on a test set.
- Privacy in the real world is typically measured as the risk of information disclosure to the parties involved. Statistical disclosure control defines that if confidential information of an entity can be identified in the disclosed (masked) data with an unacceptably narrow estimation, or if it can be exactly identified with a high level of confidence, then this poses a privacy risk of disclosure. To assess this risk, one practical approach is to conduct re-identification studies by linking values from a masked dataset to an external dataset. Additionally, some algorithms come with formally proven privacy guarantees, but these are usually not available for the entire PPRL pipeline.
- Computational costs can be measured both empirically and theoretically. Empirical measurements include runtime, memory requirements, communication volume, number of comparisons or operations, or total compute costs on the target platform. Theoretical measurement refers to the big-O notation analysis of the algorithm.
- Fairness is defined as the correctness of results in relation to different subgroups of entities (usually individuals). In PPRL fairness can be taken into consideration through the use of decision boundary fairness measures in classifier training.
Privacy methods
Privacy systems and methods used in PPRL
- Cryptography methods are used to enable secure multi-party computation required by PPRL, such as homomorphic encryptions, secret sharing, and secure vector operations. These are provably secure and accurate, but expensive computationally.
- Embedding techniques with privacy assurances enable data mapping onto multi-dimensional vectors while preserving the semantic distances between the original data. More recent work proposed the FEDERAL framework that can embed both string and numerical data while providing the accuracy and privacy guarantees under various privacy attack models described above.
- Differential privacy is a rigorous definition that provides guarantees of an individual’s indistinguishability, regardless of whether their record is present in the data. However, it is usually done by perturbing data with noise, which adds utility loss and increases the volume of data. This led to the development of the output-constrained differential privacy model that allows the disclosure of matching records while being insensitive to the presence or absence of a single non-matching record.
- Probabilistic data structures are also a popular method for encoding data because of the controllable trade-off between privacy and utility, and their high efficiency. A large evaluation of bloom filter methods showed that probabilistic techniques in PPRL can achieve linkage quality comparable to using unencoded records.


