
Notice:
This post is older than 5 years – the content might be outdated.
Edge Computing has been a growing topic for the past few years. In this article we’ll give you an overview over Edge Computing, discuss its advantages, explain a sample architecture as well as the classes of use cases it can be applied to.
What is Edge Computing?
In general, Edge Computing is the process of performing computing tasks physically close to target devices, rather than in the cloud or on the device itself. Over the past decades we’ve seen different architectural patterns for systems. Depending on the bottleneck of the system it was designed as a centralized or decentralized system. The growing amount of data (IoT) and the limitations of the networking layer (and computation) currently lead to a decentralized system like Edge Computing.
In lay terms it can be compared to eating locally produced food. While steaks from Argentina are delicious, the transport of the steaks comes with several disadvantages. The food has to be transported over a huge distance, leading to increased CO2 emissions, and it takes a lot of time. Furthermore, the origin of the meat is much more difficult to track and different standards for animal rights may apply. While these circumstances do not directly translate to the digital world, the line of reasoning is similar.
Advantages of Edge Computing
The main motivations for Edge Computing are the following.
- Stronger Hardware (compared to device): In today’s world many applications rely on very strong or specialized hardware. Modern machine learning algorithms, for example, work best with GPUs or tensor processing units (TPUs). Extending devices with such hardware is generally not desirable. Edge Nodes are preferable for such specialized hardware and hardware with more computing power in general.
- Better Latency (compared to cloud): If applications depend on immediate feedback (e.g. to make “real-time“ decisions), sending data to the cloud, calculating and sending the data back to the device may take too long. However, if the path is reduced to the (much closer) Edge Node and back, many use cases can be realised.
- Data throughput: Devices may produce enormous amounts of data. One single autonomous car for example may produce up to 4000 gigabytes of data per day. If every single car sent all data it generates all the way to central datacenters it would create a huge load on the network. By performing the necessary computations on Edge Nodes close to the device, most of the path can be pruned. This is especially important when considering the increasing importance of the internet of things and the rising number of devices connected to the internet.
- Reliability and robustness: The main functionality of devices should still be available, even if communications to the central cloud are impaired. This can be achieved by relying on local communication with an Edge Node which should (in theory at least) be less prone to problems. If an Edge Node fails, the devices will be shifted to an alternative Edge Node.
- Privacy: In many use cases collecting user data is required or at least useful. However, in cases where aggregated data is sufficient, the users’ privacy can be preserved by aggregating the data on the Edge Node instead of the cloud.
- Scalability: In most cases the computing power of devices is limited by their small size. Furthermore, developing a new use case that requires stronger hardware will require all possible users or the network administrator to update the devices, which limits the use cases’ adoption rate. Edge Nodes do not suffer from these problems and can be extended both very easily and continuously. Using a suitable Edge Computing framework, adding, replacing or upgrading Edge Nodes is a very simple and highly automated process.
- Adaptability: Using an Edge Node instead of a single purpose server has the added benefit of being adaptable to changing circumstances. After enabling a base environment, Edge Nodes can be easily configured to provide individual subsets of services, depending on the environment. While some use cases are only useful in cities, others may be more beneficial in rural areas. Due to the direct connection to the cloud and higher-level Edge Nodes, moving workloads and freeing up computing power for critical use cases is possible and can be done on the fly.
Architecture of Edge Computing
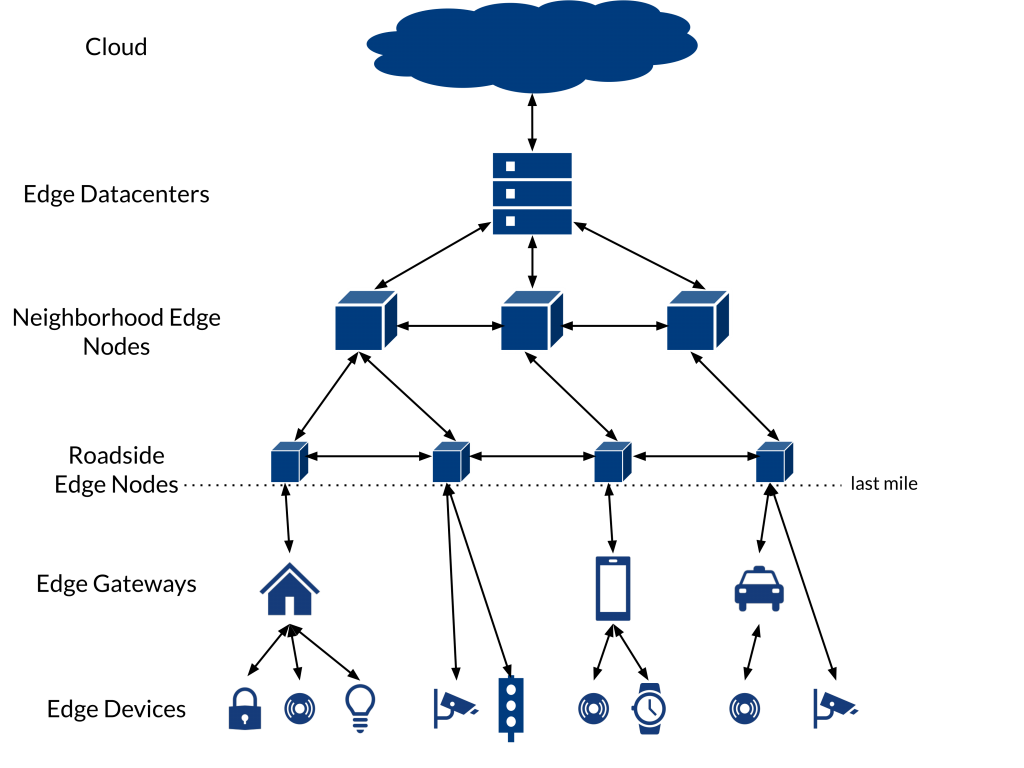
The above picture shows a typical Edge Computing architecture. It is defined by a hierarchy of computing power and latency, both of which are highest on the top level and decreasing downwards. This allows us to perform latency-critical computations as low on the hierarchy as possible and computing intensive calculations as high as necessary.
The layers are defined as follows:
- Cloud: On this layer compute power and storage are virtually limitless, but latencies and the cost of data transport to this layer can be very high. In an Edge Computing application the cloud can serve as long-term storage, coordinator of the immediate lower levels or powerful resource for irregular tasks.
- Edge Node: These nodes are located before the last mile of the network, also known as “downstream“. Edge Nodes are devices capable of routing network traffic and usually also possess high compute power. They can range from base stations, routers or switches up to small-scale data centers.
- Edge Gateway: Edge Gateways are similar to Edge Nodes but less powerful.They are capable of speaking most common protocols and can manage computations that do not require specialized hardware such as GPUs. Devices on this layer are often used to translate for devices on lower layers or to serve as a platform for the lower-level devices. This includes devices such as mobile phones, cars as well as sensors, eg. cameras and motion detectors.
- Edge Devices: On this layer you’ll find small devices with very limited resources such as single sensors or embedded systems. These devices are usually purpose-built for a single type of computation and often limited in their communication capabilities. Devices on this layer might be smart watches, traffic lights or environmental sensors.
Communication in an Edge Computing application is not limited to inter-layer traffic, but can also happen inside a layer in peer-to-peer fashion. This enables faster communication between devices in different mists, which are able to communicate through their respective Edge Nodes. It can also further reduce network load and cost by omitting communication over the internet. Whether this is desired or not depends on the specific use cases and possible security concerns.
Theoretically there is no limitation of Edge Devices connected to an Edge Node and you can think of multiple Edge Nodes in different locations, each connected to the same cloud and its own physically close devices.
Use case classes for Edge Computing
In order to get a better overview about the possible use cases in edge computing we decided to create “use case classes“. These consolidate use cases that are related to a similar problem. In our research we found multiple such use case classes.
Let us consider one common topic for the use case classes. The topics of “Smart Home“ and “Smart Business“ have been getting more and more attention over the past years and can be seen as an example for Edge Computing. Most smart home systems offer multiple (Edge) devices that have very low computational power and are mostly used for actions (e.g. a light that can be turned on and off, a plug that can turn devices on and off) or sensors (e.g. a motion sensor or sensors noticing whether a window has been opened). These are controlled by one central unit (the Edge Node that can often be controlled by a smartphone app). Now, using this scenario, let us have a look at different use case classes for such a system:
- Offloading: Moving computationally intensive tasks to a more powerful machine. One sub-class of this class is the machine learning use cases, where specialized hardware (e.g. graphics cards or tensor processing units) can be very helpful, while expensive. In our smart home scenario we might want to open the front door only if the person detected by a strategically placed camera is a member of a predefined list of persons. If the systems consists of only a single camera, this could be solved by attaching a tensor processing unit to the camera. But in systems with multiple cameras, this will get very expensive and most of the available computing power would be wasted. Having the computing power concentrated at one point (the Edge Node) helps with these problems.
- Content Scaling: Scale or transform content to a different format to save network bandwidth. Think of a smart home with multiple security cameras that stream their images to a server. These cameras might not be uniform and have different formats/resolutions. Thus, having one central instance that converts all these streams into uniform formats and resolutions is useful to not waste any resources on the server or the devices.
- Local Connectivity: Connect the devices locally in a way that is independent from an outside (often internet) connection. Many smart home systems use a form of local communication that is independent from the internet connection. The Philips hue ecosystem for example relies on zigbee. In such cases the local connectivity aspect can be used to enable users to control their smart home system locally, without relying on the servers of the manufacturer of the devices.
- Edge Content Delivery: Deliver content through the Edge network, similar to a traditional CDN. Consider a big apartment building with a central network. In such a system, content that is expected to be used by multiple of the inhabitants (e.g. the latest episode of Game of Thrones on its release day) could be loaded to the central network in advance, lowering the load on the network in the evening, since the data can be accessed on the (fast) central network.
- Aggregation (Multi-Sensor Fusion): Use information from multiple data sources located on the Edge and aggregate them in some form or other. In a smart home scenario typical data sensors are weather sensors, contact sensors for windows and doors, moisture sensors for plants as well as smart thermostats. Using the data from these sensors combined, the central unit can deduce useful suggestions for the user. For example, watering the plants can be automatically disabled before a rainy day.
These use case classes are not disjoint and there are many examples that can reasonably be placed into multiple use case classes. Let us imagine an example use case in a new scenario, just for clarity:
Consider a traffic network of a city. Cameras are filming multiple roads leading to a big intersection. The city wants to make this intersection as efficient as possible and by adjusting the traffic lights dependent on the number of cars arriving from each direction. To this end, the video streams from the different traffic cameras are automatically sent to a nearby Edge Node. On the Edge Node an object detection algorithm is applied to each of the arriving video streams, counting the cars. This information is used to dynamically adjust the timing of the traffic lights on the intersection. Clearly, this use case belongs to the aggregation class, since data from multiple data sources is required. But it also belongs to the offloading use case class, since counting the cars arriving from each direction could also be performed by the cameras themselves. However, since object detection is a relatively computationally intensive task, performing it on the more powerful Edge Node is preferred.
This concludes our introduction to Edge Computing. You should now understand the relevancy of Edge Computing and which advantages it can bring to cloud computing, the hierarchical architecture of Edge Computing that is defined by latency and compute power and the different use case classes, in which these advantages and the architecture shine.
Read on
Consider having a look at our Engineering and Smart Devices portfolios for more information. You might also want to head over to our job listings if you want to get your hands dirty yourself!


