
Notice:
This post is older than 5 years – the content might be outdated.
Welcome to our second blog article concerning the Redis caching engine. Here I want to introduce Redis persistence mechanics, their pros, cons and some configuration examples. Additionally I want to describe different backup and restore strategies. If you haven’t done so already, have a look at part 1 for the basics.
Overview
- How does RDB Snapshotting work?
- What is AOF Logging?
- Should I use RDB or AOF or both?
- How to backup and restore?
Redis persistence: RDB Snapshotting
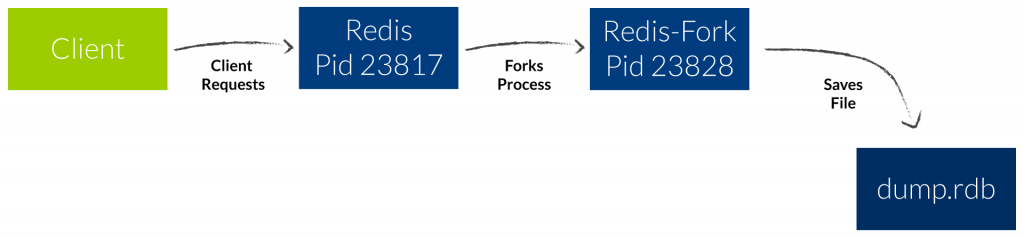
RDB Snapshotting creates a point-in-time file of your Redis data. These Files can be easily used for backup and disaster recovery. You can transfer the file to other Redis instances to bring the dataset wherever you want.
Logfile Example:
23817:M 15 Jul 13:53:10.855 * Background saving started by pid 23828
23828:C 15 Jul 13:53:10.856 * DB saved on disk
23828:C 15 Jul 13:53:10.857 * RDB: 2 MB of memory used by copy-on-write
23817:M 15 Jul 13:53:10.932 * Background saving terminated with success
As you see the original Redis (Pid 23817) will serve client requests while the fork (Pid 23828) saves the dataset on disk. The log mentions that 2 MB were used by copy-on-write during the snapshot. So in the worst case the fork will use the same amount of memory which is used by the original Redis process.
The Linux out of memory (OOM) killer will kill the fork if the system runs low on memory. To avoid this you can tune a kernel parameter at your Redis servers. Just add ‚vm.overcommit_memory = 1‘ to /etc/sysctl.conf and then reboot or run the command sysctl vm.overcommit_memory=1 for the change to take effect.
Configuration
Here you will find the configuration options and a short description.
- save 900 1/save 300 10/save 60 10000: These are the default settings to tell Redis when it should start saving the dataset. Rule: save after x seconds if at least x keys changed
- stop-writes-on-bgsave-error yes: When backgroundsaving fails, should the Redis stop accepting writes. If your monitoring for disk, permissions and so forth works well, set it to no.
- rdbcompression yes: Uses a bit more CPU when doing LZF compression, but reduces the filesize.
- dbfilename dump.rdb: Choose the name of your snapshot file
- rdbchecksum yes: Creates a CRC64 checksum at the end of the snapshot file. The Performance hit to pay during saving and loading the snapshotfile is around 10%. Set to no for maximum performance, but less resistence to corruption
- dir /var/lib/redis/: Choose the directory where to save the snapshot file.
Redis persistence: AOF Logging
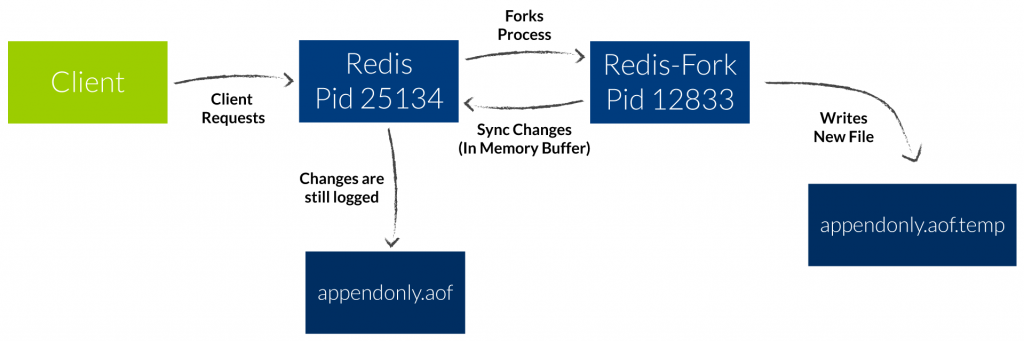
The AOF Log is an append-only logfile. All operations that change the dataset are logged one after another.
AOF logging is very robust and you can have different fsync policies to tell Redis how often you want to write the logfile. At an outage (example: kill -9 or power outage) you lose only the data written on disk after the last fsync.
The AOF fsync can cause high load due to its ongoing I/O on disk. As the log is uncompressed, its size is even bigger than the compared RDB Snapshot of the same dataset (twice the size). When the file exceeds a certain size, Redis will spawn a fork to rewrite the logfile, saving some space. The fork is human readable and even editable via editor. You could for example remove a flush all from the logfile, restart Redis, and thereby recover your dataset.
Logfile Example:
25134:M 18 Jul 13:37:39.333 * Background append only file rewriting started by pid 12833
25134:M 18 Jul 13:37:39.369 * AOF rewrite child asks to stop sending diffs.
12833:C 18 Jul 13:37:39.369 * Parent agreed to stop sending diffs. Finalizing AOF…
12833:C 18 Jul 13:37:39.369 * Concatenating 0.00 MB of AOF diff received from parent.
12833:C 18 Jul 13:37:39.369 * SYNC append only file rewrite performed
12833:C 18 Jul 13:37:39.370 * AOF rewrite: 4 MB of memory used by copy-on-write
25134:M 18 Jul 13:37:39.404 * Background AOF rewrite terminated with success
25134:M 18 Jul 13:37:39.404 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
25134:M 18 Jul 13:37:39.404 * Background AOF rewrite finished successfully
As you see the parent (pid 25134) spawns the child (pid 12833). The AOF diff is 0.00 MB as there was no change at the Redis dataset during this time.
Configuration
Here are the configuration options for AOF logging, each with a short description.
- appendonly no: Default is no. To enable choose “yes“
- appendfilename „appendonly.aof“: Choose the name of your logfile
- appendfsync everysec: everysec: sync the changes on the dataset every second (good compromise between performance and data safety), no: don’t fsync, let the OS flush the output buffer when it wants (best performance), always: fsync after every operation on the dataset (highest I/O , best data safety)
- no-appendfsync-on-rewrite no: During AOF rewrite, stop fsync, no: (data safety, but produces additional I/O), yes (outage during aof-rewrite will cause data-loss, lower I/O)
- auto-aof-rewrite-percentage 100: When the size exceeds 100% the rewrite is triggered. Set it to “0“ to disable the rewrite completely
- auto-aof-rewrite-min-size 64mb: Min Size of the File to trigger the rewrite (even if percentage is reached)
- aof-load-truncated yes: yes: A corrupted aof file will cause no exception and the server starts normally with an event at the logfile, no: Redis will crash with an error, use redis-check-aof to fix the corrupted logfile (remove incomplete commands/lines)
Should I use RDB or AOF or both?
Now that you know the basics of both methods, how do you decide which to use for which use-case? When you need maximum data protection, want easy snapshots and minimal data loss in case of an outage you can enable both features at the same time.
Redis handles both well, the RDB-Snapshot and AOF-Rewrite processes will never run at the same time. But keep in mind: When starting up, Redis will always take the AOF Logfile, as it provides the more robust solution.
If you your data is very important but you can live with a few minutes of data loss, use RDB alone. Redis starts faster, backups are easily created an RDB snapshots can be transferred. You could also save the logfile from time to time, but snapshots and backups via RDB are preferred.
For the (possibly far) future a unification of both approaches into a single method is planned.
How to backup and restore?
When using AOF log or RDB snapshots you need a process, a tool to transfer the file and a location to store it. Keep in mind that in case of a disaster all your data is lost. The goal is to backup the AOF or RDB file frequently, encrypt it and transfer it safely to a location outside the datacenter.
Here are some ideas:
- cron/systemd-timers to run the backup script/tool.
- gpg for encryption
- scp for secure transfer outside the datacenter
- Amazon S3 bucket to store it
- linux find command to cleanup old backup files
RDB Restore
To restore an RDB snapshot you have to stop the Redis server and copy the file to the data-dir location (/var/lib/redis). The owner of the file has to be redis. After you re-start the instance, the dataset is loaded from the file.
AOF Restore
To restore from an AOF log you have to stop the Redis server and copy the AOF log to the data-dir location (/var/lib/redis). The owner of the file has to be redis. Re-start the instance and Redis will execute all commands from the AOF log. If the server crashes while loading the file you may have to check and fix the corrupted file:
- Make a copy of the AOF log.
- Fix the file “redis-check-aof –fix“.
- Compare both files: diff -u
- Restart the instance with the fixed file.
I hope I was able to give you a more detailed view on the Redis persistence options and how to backup and restore your Redis datasets. Feel free to comment or share this article – and don’t forget to come back for the next article in this series, “Redis High Availbility“.
Read on
Want to find out more about the services we offer in Data Center Automation? Have a look at our website, write an email to info@inovex.de or call +49 721 619 021-0.
Join us!
Looking for a job where you can work with cutting edge technology on a daily basis? We’re currently hiring Linux Systems Engineers (m/w/d) in Karlsruhe, Pforzheim, Munich, Cologne and Hamburg!



2 Kommentare